

When multi-agent systems are worth the overhead
A multi-agent panel only helps when the agents disagree for real reasons. Forecasting is where you can check.

Chapter 24 of Machine Learning for Trading treats agents as engineering systems rather than chat interfaces. One of its capstones is a multi-agent forecasting system: several research agents gather evidence, an aggregation rule combines their probabilities, a supervisor reconciles disagreement, and the final forecast can later be scored.
The accompanying notebooks test where this architecture helps, where it adds cost, and where a simpler baseline would have been enough.
One example is the adversarial-debate notebook. A bull-bear debate ran for three rounds on a Fed-rate question. The bull ended at 0.78, the bear at 0.35, and the gap stayed fixed at 0.43 across all three rounds. The debate added more than 6,000 tokens and moved the blended forecast by one percentage point.
The result provides a practical lesson for multi-agent systems: the extra-agent stage has to justify its cost.
Multi-agent systems are easy to make look sophisticated. Add several model calls, assign roles to them, ask them to debate, and place a supervisor at the end. The harder question is whether the added structure produces independent evidence, actionable disagreement, better reconciliation, or a better-scored output than a simpler baseline.
Forecasting is a good lab for that question because the output is hard to hide. A probability can be timestamped, compared with a market price or base rate, calibrated, ablated, and scored after the event resolves.
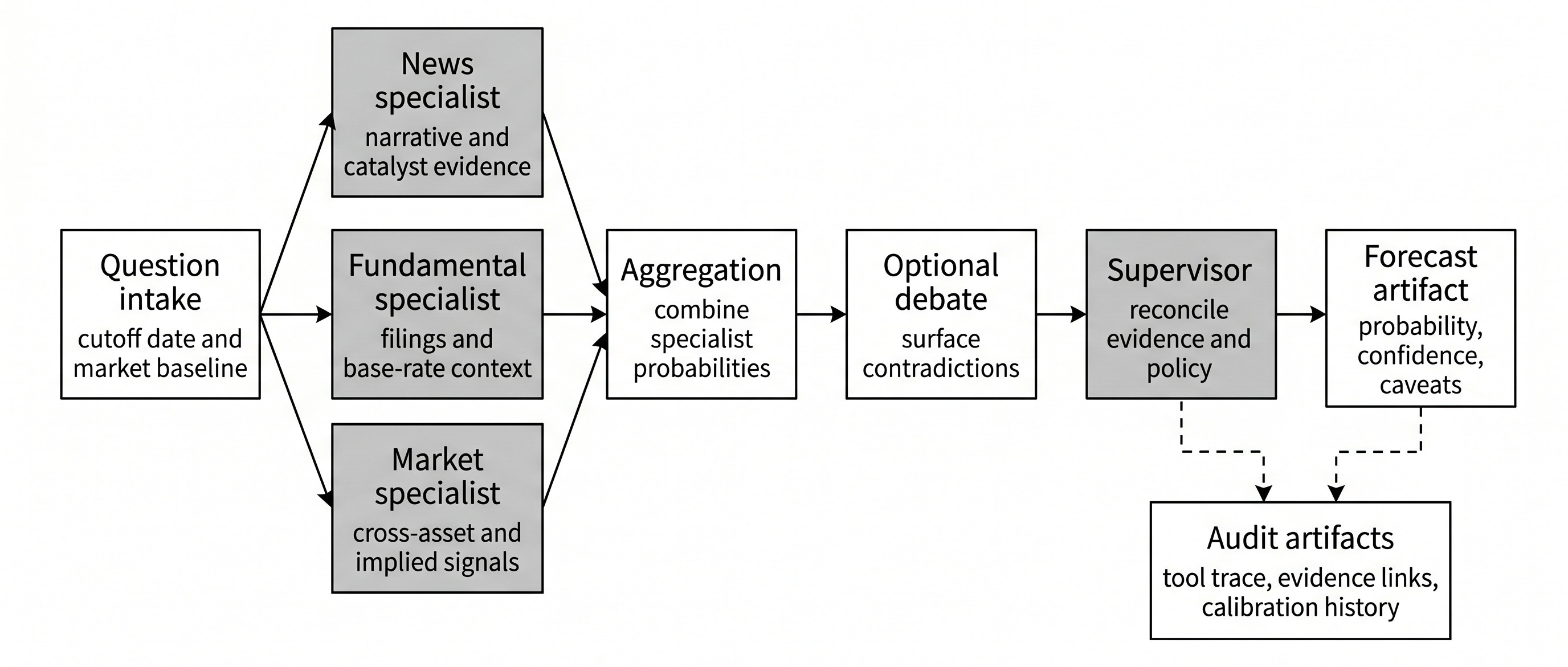
Chapter 24’s full multi-agent forecasting pipeline: specialist research agents feed aggregation, optional debate, supervisor reconciliation, a forecast artifact, and audit artifacts. The question for this issue is which stages earn their cost.
The realistic standard
Bridgewater AIA Labs’ AIA Forecaster technical report is one of the clearest public blueprints for this pattern.
The report describes a multi-agent forecasting system with agentic search, supervisor reconciliation, and statistical calibration. It reports performance that is statistically indistinguishable from human superforecasters on ForecastBench, but it also reports a more sobering result on liquid prediction-market questions: AIA Forecaster underperforms the market consensus on its own. The interesting result is the ensemble. On that harder benchmark, combining market prices with AIA forecasts performs better than either source alone.
The standard for agent systems in this setting is narrower than market replacement. The agent has to add information that survives comparison with a strong baseline.
The Chapter 24 implementation starts with a single ReAct research loop, then adds tool contracts, explicit state, multi-agent forecasting, evaluation, governance, and a separate ML4T research operator. This issue focuses on the forecasting system because it most clearly exposes the multi-agent design.
The pipeline
The forecasting agent example starts with a question that can be resolved - on a prediction market, at a later stage.
“Will inflation be high?” is not enough. A resolved example from the Lightning Lesson is precise enough to score: “Will US core PCE for April 2026 exceed 0.3% month over month in the BEA Personal Income and Outlays release scheduled for May 28, 2026?” The BEA release reported core PCE at 0.2% month over month, so the event resolved “no.”
After the question is fixed, several research agents work independently. Each agent searches for evidence, records what it finds, reasons about the result, and returns a probability with supporting evidence. In the AIA design, these agents are parallel evidence-gathering runs rather than role-playing characters.
The system then combines the probabilities. The simple mean is the reference point. The median and trimmed mean reduce the influence of outliers. Extremization pushes an aggregate away from 0.5 when forecasters are treated as sufficiently independent.
One diversity adjustment used in the Chapter 24 notebooks is:
Here, D quantifies how far the aggregate can deviate from 0.5 after accounting for dependence among forecasters. With three independent forecasters, D = 1.73. At pairwise correlation 0.7, it falls to 1.12. Three correlated agents are only marginally more informative than a single agent.
A supervisor can inspect disagreement after aggregation. The supervisor policy is narrow: identify the source of disagreement, run clarifying searches when evidence is missing, and override the aggregate only when the new evidence clears a stated confidence threshold. Otherwise the aggregate remains the forecast.
Calibration comes last. It can correct systematic probability bias only when estimated on resolved forecasts outside the run being scored. It cannot repair a contaminated question, a weak evidence process, or three agents that all missed the same fact.
The stored forecast record should contain the question, resolution source, cutoff, evidence references, agent forecasts, aggregate, supervisor action, calibration setting, model configuration, market or base-rate baseline, final probability, outcome, and score.
What the notebooks show
The Chapter 24 notebooks include weak results rather than only clean demonstrations to show the reality of agent system development (notebooks will be released closer to publication, late June/early July).
In the notebook research_agent, two identical research agents working on the same Fed-rate question returned 0.75 and 0.72. In the notebook multi_agent_research, three agents on a pinned Fed-hike question all returned 0.25, even though their search paths differed slightly. Temperature alone did not create an informative panel.
In the notebook aggregation_math, the diversity factor makes the cost of correlation explicit. Adding agents helps only if they bring different information. If they share the same model, tools, retrieval sources, and priors, the panel can appear broad while behaving like a single repeated forecast.
In adversarial_debate, debate lengthened the trace without narrowing the gap. The notebook shows why debate needs an ablation rather than just a transcript. If the debate does not move beliefs, reveal missing evidence, or improve resolved-outcome scores, it is theater with a token bill.
In evaluation_and_governance, the evaluation panel compares the pipeline with simpler variants using Brier score, log score, expected calibration error, sharpness, ablations, and a market baseline. The panel is small and carries contamination caveats, so it illustrates the scoring workflow rather than a performance claim.
The design rule is simple: keep a component only when it improves the forecast record, the diagnosis, or the evaluation.
What adjacent work adds
The relevant papers add design lessons rather than slogans.
Bridgewater’s AIA Forecaster supplies the forecasting blueprint: agentic search, multiple independent forecasts, supervisor reconciliation, calibration, and comparison with market consensus.
AlphaAgents matters here less for its reported portfolio results than for its role-structured design: fundamental, sentiment, and valuation agents with debate as the reconciliation mechanism.
Recent work on scaling agent systems makes the general point explicit: more agents can help on decomposable tasks and hurt on sequential ones. Coordination overhead, redundancy, and error amplification are design variables.
Where the pattern fits
The workshop uses forecasting because the work is measurable. That does not make forecasting a universal test case for agents.
Sequential execution tasks usually need a workflow, not a panel of agents. A deterministic data-cleaning step, for example, should not become a debate among models. Evidence-gathering tasks may require one strong research agent at first, but several later. Multi-agent design becomes more plausible when the task has competing interpretations, missing evidence, and a decision artifact that can be compared with a baseline.
Forecasting gives that problem a disciplined form. The artifact is a probability. The baseline may be a market price, base rate, consensus forecast, or simpler model. The outcome eventually resolves. The system can be wrong in a measurable way.
That is why this topic belongs in ML4T. It is close enough to trading and research to matter, but constrained enough to evaluate.
What we are building
The companion forecasting-agent codebase turns the AIA pattern into a runnable system, including a CLI, configuration profiles, read-only prediction-market connectors, SQLite persistence, a Streamlit dashboard, deterministic replay mode, local and hosted model profiles, and ablation settings.
The free Lightning Lesson on Thursday, June 18, 2026, walks through this architecture: independent research agents, aggregation, supervisor reconciliation, calibration, and scoring. The practical goal is to inspect, test, ablate, and score the system rather than trust the final paragraph.
The full hands-on workshop, Building Multi-Agent Forecasting Systems, runs Saturday, June 27, 2026, 10am-5pm ET. Participants work with config profiles, replay traces, aggregation settings, supervisor policy, calibration diagnostics, and resolved-outcome scores. The guaranteed path uses deterministic replay, so the exercises do not depend on API keys or live network access. The connectors are read-only.
Use five questions to judge the result:
Did independent agents produce independent evidence?
Did aggregation improve on the simple mean?
Did the supervisor find missing evidence or merely override?
Did calibration improve reliability without hiding a weak evidence process?
Did the system improve on a market price, base rate, or simpler model?
Tomorrow’s issue uses the World Cup Forecast Lab as a public forecasting surface. Later issues go deeper into AIA Forecaster, multi-agent diversity, and the ML4T research operator.
Register for the free Lightning Lesson: Build Multi-Agent Systems You Can Audit
Register for the workshop: Building Multi-Agent Forecasting Systems