

Watching the World Cup With a Forecasting Agent
A live World Cup lab for model priors, noisy match news, market comparisons, and scoreable agent calls.

The World Cup is one of the few forecasting problems people argue about for pleasure, and it rarely lets a confident prior off the hook.
Morocco reached the semifinal in 2022. Costa Rica topped a 2014 group that included Uruguay, Italy, and England. Germany won the tournament in 2014, then went out in the group stage in 2018 and again in 2022. The tournament has a long record of embarrassing anyone too sure about it.
That is exactly what makes it a fun public forecasting lab. The questions are the ones everyone already has an opinion on, the answers come back within hours, and once the match is over, a forecast has very little room to talk its way out of a bad call.
By the morning of June 16, the World Cup Forecast Agent had already built a record worth picking apart. Spain was a 75.6% favorite in the model and an 80.0% favorite in the agent’s call; Cape Verde held Spain to 0-0. Saudi Arabia-Uruguay and Iran-New Zealand ran the same way: the agent nudged the favorite higher, and both matches finished level.
That is the reason for publishing the lab while the tournament is still underway. Every pre-match number is locked, the trace behind the agent’s adjustment is stored, and the call is scored once the result is in.
Before kickoff, the traces can read sensibly. A few hours later, the scoreboard may have a different opinion.
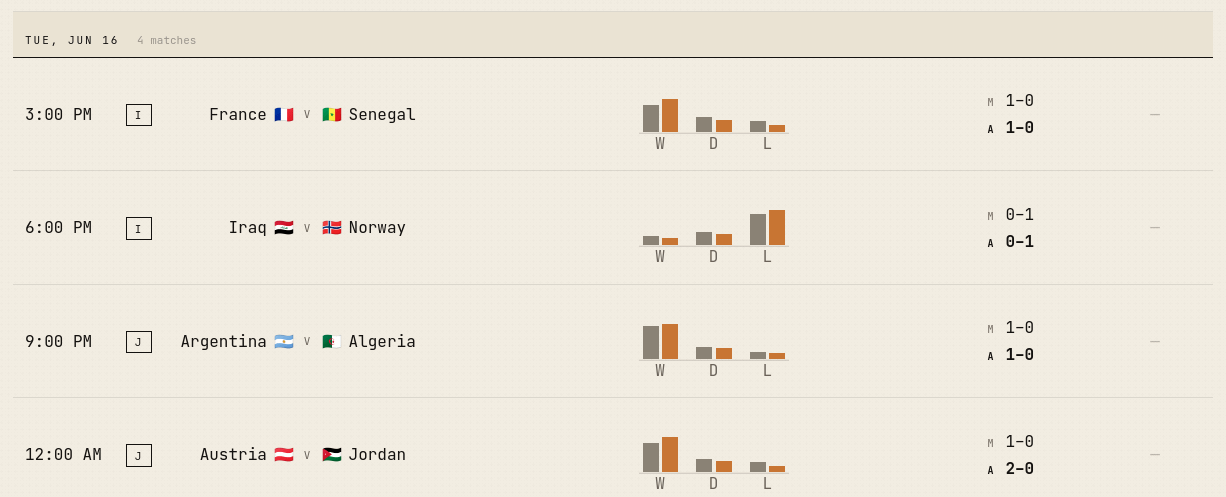
A June 16 fixture strip from the live app. Each row shows the model call and the agent call before kickoff, so readers can see the adjustment before the result arrives.
See below for a free lightning lesson about building multi-agent forecasting systems.
The model gives the prior
The baseline starts with a familiar statistical idea: estimate each team’s attacking and defensive strength from international results, weight those results by competition and recency, then simulate the tournament bracket.
As of the current public run, the model’s leading champion probabilities are:
Spain: 14.2%
Brazil: 12.9%
Argentina: 11.8%
England: 9.3%
France: 6.5%
Portugal: 6.5%
Germany: 5.0%
Colombia: 4.6%
Treat those as a dated snapshot. They are where the forecast starts, not where it ends.
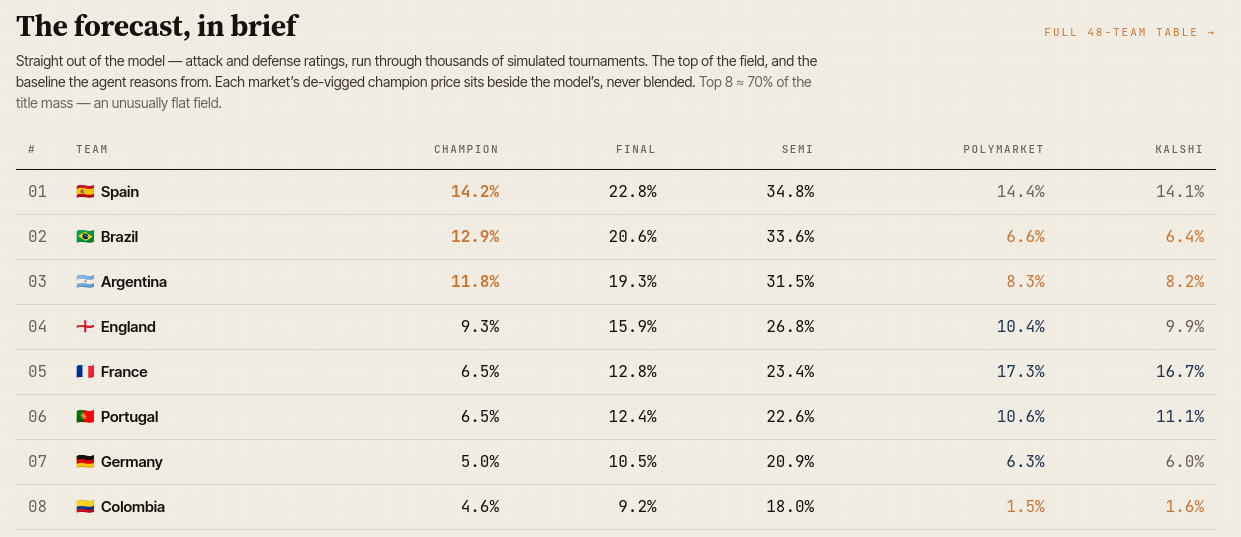
The live forecast table keeps model champion probabilities alongside Polymarket and Kalshi prices, rather than blending them into a single consensus number.
The baseline is useful because it is systematic. It is fit on more than 47,000 international results, checked in walk-forward tests, and straightforward to score after the fact. The forecast table sets the model’s champion odds next to Polymarket and Kalshi prices without averaging the three, which keeps the disagreement on the page rather than dissolving it into a single tidy consensus figure.
The baseline is also restricted to variables we can reconstruct over time. Injuries, lineup news, weather, travel, squad value, current form: a model could use all of it if each input were a clean, point-in-time history. Most of it does not. Some arrives as prose; some is patchy; and for many variables, there is no decades-long archive of comparable snapshots from the past. Pour today’s headline into a model that was never trained on yesterday’s headlines, and you have introduced a new bias, not improved the prior.
That gap is the agent’s job. It can work with current, partly structured information without demanding a 50-year feature history. In production, the next step would be to rebuild richer point-in-time datasets and tune prompts, tools, and aggregation rules against historical cases. This app runs the lighter version: hold the quantitative prior steady, let the agent make a separate context adjustment, and score that adjustment on its own.
The agent calls the matchup
Before each match, the agent receives the model’s win/draw/loss probabilities, expected goals, recent form, head-to-head history, availability signals, key players, match conditions, a relative squad-value signal, and, when available, recent search results.
The part closest to Bridgewater AIA Labs’ AIA Forecaster is the research step. The agent first decides what is actually worth checking for a fixture: a late fitness scare, a suspension, a venue condition, a question about one specific player. It then runs a brief Tavily search, retains the sources relevant to the question, and files the query trace alongside the forecast.
The squad-value signal is kept relative by design: rank within the 48-team field, percentile, value ratio, and marquee names rather than raw euro totals. That gives the agent a current-talent check against a prior built from results, without pretending a transfer-market price tag is a starting eleven. It is a serviceable proxy that still carries the usual biases around age, league, club brand, and the transfer market itself.
The trace is what turns “the agent looked into the match” into something a reader can examine. For the June 16 France-Senegal call, the agent ran three searches, kept nine sources, and moved France from 50.3% to 61.7%. The source list included a piece flagging William Saliba as doubtful and a later one that walked some of that worry back. The agent is reading a noisy evidence stream, not the truth; the trace lets a reader see what it leaned on and judge whether the move was earned.
The forecast itself comes from a small ensemble of language model calls. Each one returns win/draw/loss probabilities, a scoreline distribution, and a factor-by-factor account of its reasoning. The system aggregates those passes into a single forecast and publishes it as the agent’s call, set beside the statistical model rather than folded into it.

A single agent call card from the live app. The card exposes the model-to-agent shift, likely score, short rationale, source count, and grading status.
What the live record adds
A tournament forecast table is easy to publish and easy to forget by the weekend. The World Cup Forecast Agent pulls apart the pieces such tables usually blend:
the model prior
the market’s outside view
the match’s current context
the agent’s reading of it
the eventual score
A market disagreement is not an injury note. A model probability, a research summary, and a language model’s explanation are three different objects. Holding them apart makes the forecast inspectable and scoreable.
That turns the World Cup into a gentle version of a harder ML4T problem. Many forecasting workflows begin with a quantitative prior and then have to wrap it in messy, recent, and largely unstructured information. The question that matters is whether the agent contributes a distinct, reviewable adjustment around the model or just restates it in livelier language.
Football makes that concrete. The match is played. The call can be checked. The scoreboard does the rest.
The live app is already showing its shape. As of the June 16 morning snapshot, 16 calls had been graded, with agent and model tied at 37.5% top-pick accuracy. The model’s live Brier score was 0.7271 against 0.704 for the naive-prior floor. Lower is better, so the model had not yet pulled clear of the floor, which itself was hitting 43.8% on the same 16 matches. Sixteen games is far too few to render a verdict, but the machinery is already doing its work: publish the call, score the result, let the record stack up.
The scorecard uses multiclass Brier for match outcomes, with signed per-call deltas showing whether each agent adjustment helped or hurt the model’s score. By the end of the tournament, the bar should be higher than “the agent sounded informed.” The adjustment has to improve the scoring record, sharpen the diagnosis, or both.
Why this belongs with the forecasting-agent workshop
The World Cup build is intentionally lightweight. It is the playful cousin of Bridgewater AIA Labs’ AIA Forecaster: start from a prior, pull current evidence, run independent forecast passes, aggregate them, store the trace, and score the call once it resolves.
The differences are worth being explicit about. The AIA technical report includes supervisor reconciliation and statistical calibration that this app does not claim to reproduce. AIA’s result is also more interesting than the usual “agent beats the market” story: on a liquid-markets benchmark, the agent underperformed market consensus on its own, while an ensemble of AIA forecasts and that same consensus beat the consensus alone. That is why this app keeps model, market, and agent in view at the same time.
Inside ML4T, this is the second live forecasting-agent surface. The ML4T Agent Lab tracks AIA-style questions across Polymarket and Kalshi; the World Cup app brings the same discipline, logged priors, sourced adjustments, and scored outcomes, to a tournament anyone can follow.
The workshop pushes these choices in a less-forgiving setting: independent research, reconciliation, calibration, ablations, and replayable traces. The World Cup app is the easy way in. You can pull up a match, disagree with the number, and look at exactly what the agent checked before kickoff.
How to read the live app
There are a few good places to start. The model view carries champion odds, match probabilities, team ratings, and market comparisons. The agent view holds the upcoming and resolved calls: the model-to-agent shift, the factor trace, the searches and sources, the date each was generated. The scorecard is where the misses surface. Once a result lands, every pre-match call is graded against both the outcome and the model.
It will be wrong, and often. Football is low-scoring, noisy, and decided by small events that can swamp reasonable priors. That is most of the reason to publish the record at all.
Watch the matches, argue with the numbers, and check back as the scoreboard fills in.
World Cup Forecast Agent live app
Learn how to build multi-agent forecasting systems
If you want to see how the architecture travels beyond football, next week’s free Maven Lightning Lesson walks through the design of auditable multi-agent systems: Build Multi-Agent Systems You Can Audit.
The full hands-on workshop is here: Building Multi-Agent Forecasting Systems.