

Six libraries, one workflow
Six public libraries now cover the reusable parts of the ML4T workflow: data, features, domain-specific models, diagnostics, backtesting, and live trading.

A notebook can demonstrate a workflow. It rarely makes the workflow reusable. The harder problem is preserving the assumptions that make a result interpretable: data provenance, label construction, validation design, execution semantics, and deployment controls.
That is the change this spring. The ML4T workflow now has a public software layer that readers can inspect and pressure-test, rather than reconstructing everything from scattered notebooks and chapter code.
Six libraries now carry the main parts of that loop:
ml4t-dataml4t-engineerml4t-modelsml4t-diagnosticml4t-backtestml4t-live
The stack is not equally mature; most are in public beta, ml4t-live is still alpha, and ml4t-models is the most recent addition. Even so, the reusable layer is now concrete enough for readers to run, inspect, and break.
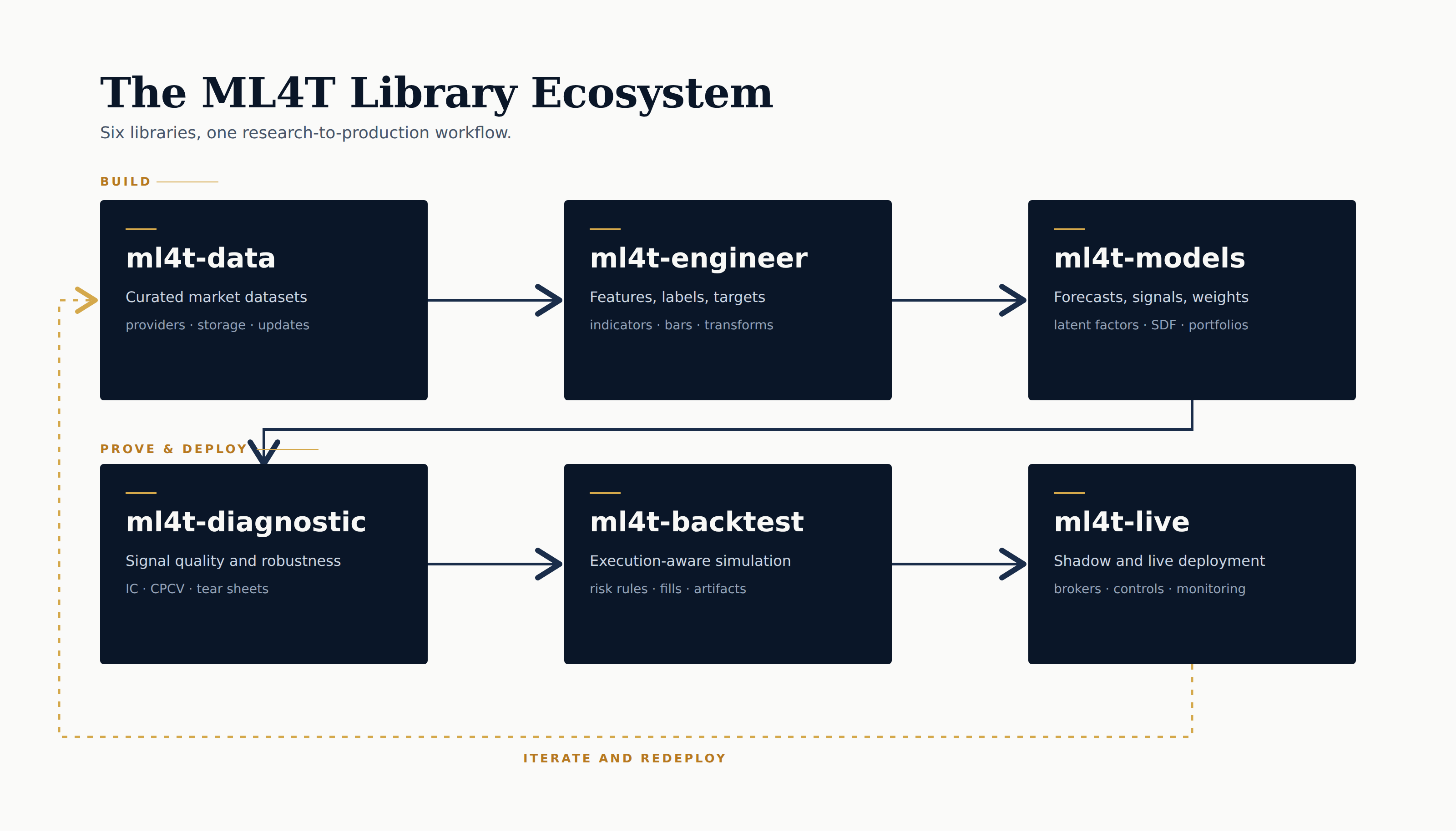
The ML4T library ecosystem is a six-step research-to-production workflow: ml4t-data to ml4t-engineer to ml4t-models on the build path, then ml4t-diagnostic to ml4t-backtest to ml4t-live on the prove-and-deploy path, with an iterate-and-redeploy loop back to data.
From teaching material to professional workflow
The six libraries line up with the actual research and deployment sequence:
ml4t-dataacquires, stores, and refreshes dataml4t-engineerbuilds features, labels, and leakage-safe training inputsml4t-modelspackages finance-native model families and hands predictions downstreamml4t-diagnosticasks whether the signal survives statistical scrutinyml4t-backtestsimulates execution under explicit behavioral assumptionsml4t-livecarries the same strategy surface into shadow, paper, and live operation
That means a reader can now do something much more concrete than “learn the workflow.” They can pull a futures or equities panel with ml4t-data, construct features and targets with ml4t-engineer, train or score them with ml4t-models, test IC stability and multiple-testing risk with ml4t-diagnostic, simulate next-bar or quote-aware execution in ml4t-backtest, and then carry the same strategy surface into ml4t-live shadow mode. That is a more concrete workflow than another abstract essay about process.
Build
ml4t-data
Every quant workflow begins with data, and data engineering failures often stay invisible until they become expensive. ml4t-data is the acquisition, storage, and refresh layer for the rest of the workflow.
Its core abstraction is a DataManager that provides a single interface for fetching, storing, updating, and loading data across providers. Breadth matters: about 20 provider adapters spanning equities, crypto, futures, FX, macro series, prediction markets, and factor data.
The more important part is that the package treats data as an ongoing research asset rather than a one-off notebook download, with local Parquet storage, metadata-backed refresh workflows, gap detection, backfills, and validation in the same layer. That is why the futures and the commitment-of-traders (COT) modules matter. They solve recurring workflow problems that simple wrappers usually ignore: bulk futures ingestion, continuous contract construction, and a point-in-time combination of weekly positioning data with market series.
ml4t-engineer
ml4t-engineer is where raw market data starts becoming something a model can learn from.
It includes 120 features across 11 categories, as well as triple-barrier labeling, alternative bars, feature discovery, fractional differencing, preprocessing, and leakage-safe dataset-building utilities. The important design choice is that feature construction, label construction, and ML-ready dataset preparation are all in one package rather than scattered across custom scripts.
These steps are not independent. Triple-barrier labels, ATR-scaled barriers, volume and dollar bars, tick-imbalance bars, fractional differencing, registry-driven discovery, and train-only preprocessing all change the shape of the learning problem. Treating them as one layer is a workflow choice, not just an API choice.
The validation posture is also concrete. The library shows explicit validation against TA-Lib-compatible features and AFML-style labeling methods, which is the right kind of proof for software that sits directly between market data and model training.
ml4t-models
ml4t-models is the newest and narrowest of the six, but it has a clear modeling point of view.
It starts from finance-native contracts: persistent panels, ragged cross-sections, portfolio sequences, structural factor extraction, stochastic discount factor learning, direct asset prediction, and end-to-end portfolio allocation.
The public surface is correspondingly specific. The library includes latent factor estimators such as PCA, Risk-Premium PCA (RPPCA), Instrumented PCA (IPCA), and Conditional Autoencoder (CAE) variants; a stochastic discount factor model; a supervised autoencoder for direct asset prediction; and portfolio-learning models for linear, LSTM, and deeper allocation settings. It also includes helpers that pass predictions and weight frames to the backtest and diagnostic layers, rather than treating modeling as an isolated exercise.
Prove and deploy
ml4t-diagnostic
ml4t-diagnostic is the part of the ML4T stack that asks the hardest question, last-mile research too often postpones: is there a real signal here, or just activity that looked convincing in the sample?
Its public surface leans into HAC-adjusted information coefficients, purged and combinatorial cross-validation, deflated Sharpe, false-discovery control, PBO, feature selection, structured backtest reporting, and template-based tearsheets.
Signal validation, statistical corrections, feature diagnostics, and backtest reporting live in one place. That makes it easier to separate prediction-quality problems from portfolio-translation problems and to ask whether an apparent result remains credible once multiple testing, autocorrelation, and leakage risks are accounted for honestly.
ml4t-backtest
Backtesting is crowded, which is one reason ml4t-backtest needs a clearer claim than “another framework.”
It is an event-driven simulator with explicit execution semantics and parity profiles that make comparisons meaningful rather than vague. The package emphasizes same-bar and next-bar execution modes, quote-aware fills, position-level and portfolio-level risk rules, and profiles spanning common frameworks, plus a conservative, realistic mode.
It also preserves inspectable artifacts after the run: fills, trades, portfolio state, predictions, and resolved config snapshots. That is what makes the bridge into ml4t-diagnostic reliable.
ml4t-live
Last but not least, ml4t-live is one of the more recent additions to the group.
It extends the workflow into a staged operation. The same Strategy interface is used in ml4t-backtest carries into live or shadow trading with broker adapters, feed adapters, safety controls, reconciliation, preflight checks, and execution journaling.
ml4t-live is built around staged deployment: shadow mode first, then paper trading, then live operation with explicit controls around stale data, position limits, order limits, drawdown limits, and kill-switch persistence. That is a much more honest view of production than pretending a strategy is “deployed” once an API key works.
Where to start
The best starting point depends on the problem you already have.
If you need repeatable acquisition and updates:
ml4t-dataquickstartml4t-dataprovidersml4t-dataincremental updates
If you already have data and need ML-ready features and labels:
ml4t-engineerquickstartml4t-engineerlabeling guideml4t-engineerdataset builder
If you have signals and want to test credibility:
ml4t-diagnosticquickstartml4t-diagnosticworkflowsml4t-diagnosticstatistical testsml4t-diagnosticbacktest tearsheets
If you want to compare execution assumptions:
ml4t-backtestquickstartml4t-backtestprofilesml4t-backtestexecution semantics
If you want the safest path from backtest to production:
ml4t-livequickstartml4t-liverisk guideml4t-liveexamples guideml4t-liveoperator guide
If you want to inspect the finance-native model layer:
ml4t-modelsdocsml4t-modelsquickstartml4t/modelsrepo
I wanted to start this newsletter run with the libraries because they are the parts that readers can use immediately.
People in this field already know they need cleaner data pipelines, leak-aware feature work, honest validation, realistic execution, and safer production handoff. The question is whether those principles have been turned into reusable software with sufficient structure to improve how people actually work.
This issue maps the public software layer. Each library is large enough to deserve its own treatment later. For now, the job is simply to make that layer visible.
Useful feedback starts where these abstractions break against real workflows: provider gaps, labeling edge cases, diagnostics that need different assumptions, execution profiles that do not match a venue, or model contracts that fail on ragged panels.