

New Release: From Data to Model-Ready Evidence
The ML4T code release for Chapters 6-10 covers the research framework, labels, feature engineering, model-based features, and text features.

This ML4T code release covers Chapters 6-10 of the third edition. These chapters sit between the data layer and the model chapters.
The first release covered the data side: market data, microstructure, alternative data, synthetic data, and the data/ package. This release adds the next layer: the trading setup, labels, features, diagnostics, validation checks, and point-in-time inputs.
Here, model-ready evidence means something practical: the target, feature timing, validation split, and search history are explicit enough to inspect before model selection starts. A lot can go wrong before an estimator enters the workflow: the label can use the wrong horizon, the feature can belong to the wrong decision time, the cross-validation split can mismatch the trading cadence, or the result can come from too many uncounted trials.
Across the five chapters, the release adds 43 notebooks:
Chapter 6: Strategy Research Framework — 2 notebooks
Chapter 7: Defining the Learning Task — 9 notebooks
Chapter 8: Financial Feature Engineering — 8 notebooks
Chapter 9: Model-Based Feature Extraction — 15 notebooks
Chapter 10: Text Feature Engineering — 9 notebooks
The release also updates the case-study directory with shared utilities and each case study’s config/setup.yaml: universe, costs, walk-forward CV, and labels.
We will work through the same research-to-production workflow as in the live Machine Learning for Trading: From Research to Production course, which starts Monday, July 6.
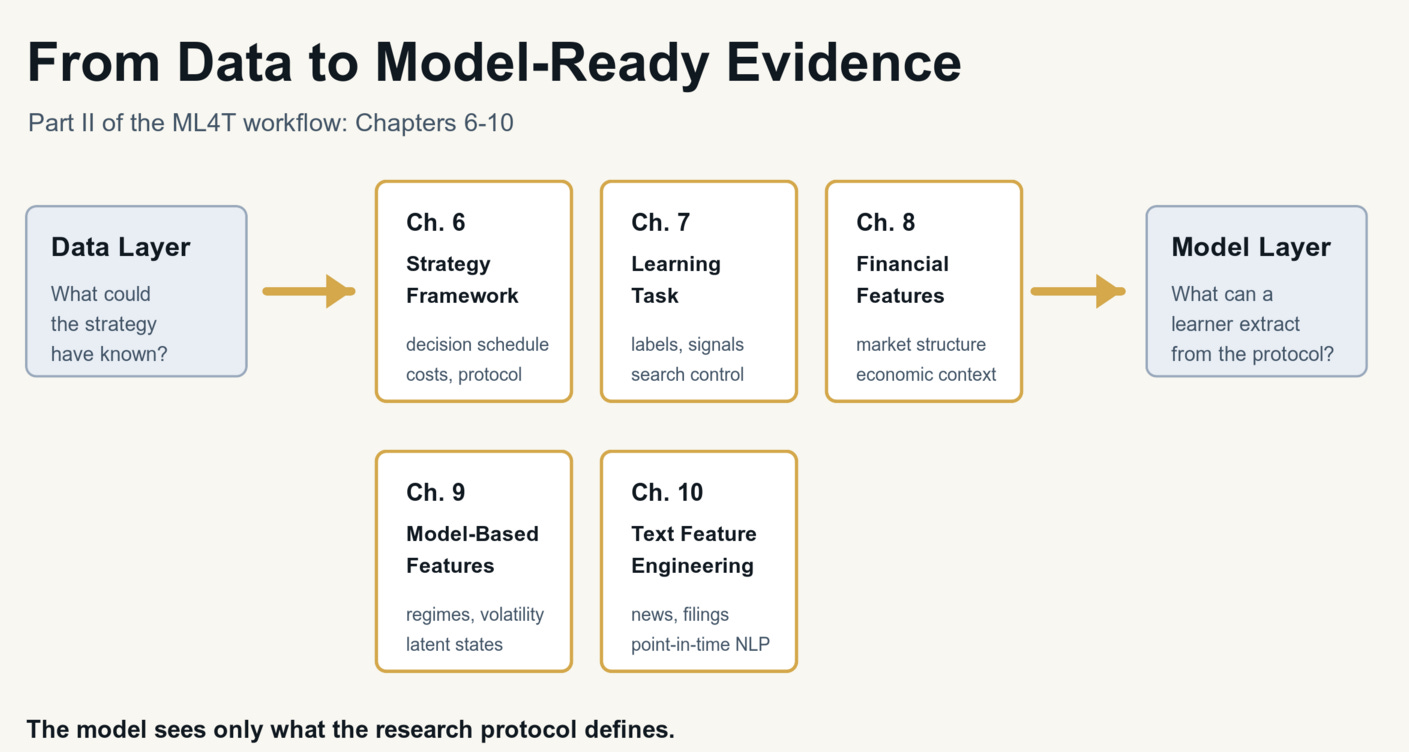
Part II connects the data chapters to the model chapters: research setup, labels, features, validation, and model-ready inputs.
Where to start
If you want the shortest path through the release:
Start with
06_strategy_definition/01_cv_foundationsfor walk-forward validation, purging, embargo, and nested CV.Start with
07_defining_the_learning_task/03_label_methodsif the prediction target is still unclear.Start with
08_financial_features/05_feature_selectionif the feature set is too broad.Start with
09_model_based_features/11_hmm_regimesif the regime state is part of the signal story.Start with
10_text_feature_engineering/09_filing_text_signalsif you need point-in-time NLP alignment.
Chapter 6: Strategy Research Framework
Chapter 6 defines a trading strategy as an executable decision process, not just a signal or model. It specifies the market, universe, decision schedule, tradability rules, score-to-position mapping, costs, constraints, evaluation metrics, and run logging.
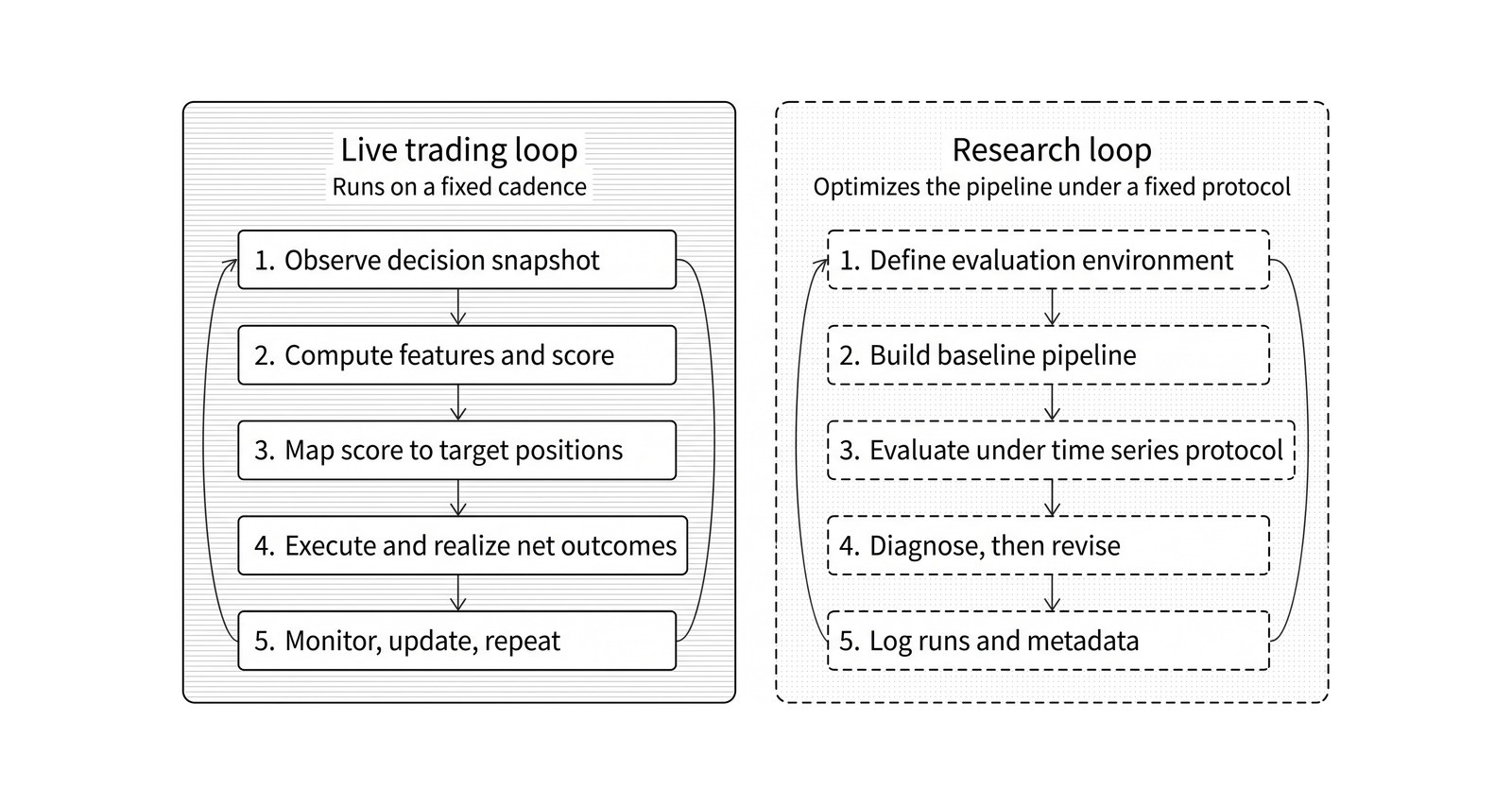
Chapter 6 separates the live trading loop from the research loop: one runs the strategy on a fixed cadence, the other improves the pipeline under a fixed setup and evaluation protocol.
The chapter also introduces the nine case studies used throughout the book, enabling strategy research to be compared across asset classes, trading cadences, and market structures.
Notebook highlights:
01_cv_foundationsbuilds walk-forward cross-validation from first principles, including decision-time admissibility, purging, embargo, calendar-aware splits, nested walk-forward validation, and combinatorial purged CV.02_case_study_overviewsummarizes the nine case studies, including datasets, asset classes, constraints, evaluation protocols, and prediction coverage across time.
Chapter 7: Defining the Learning Task
Chapter 7 turns raw but validated data into a learning problem. It builds split-aware preprocessing, label engineering, feature-label evaluation, multiple-testing checks, and lightweight causal falsification.
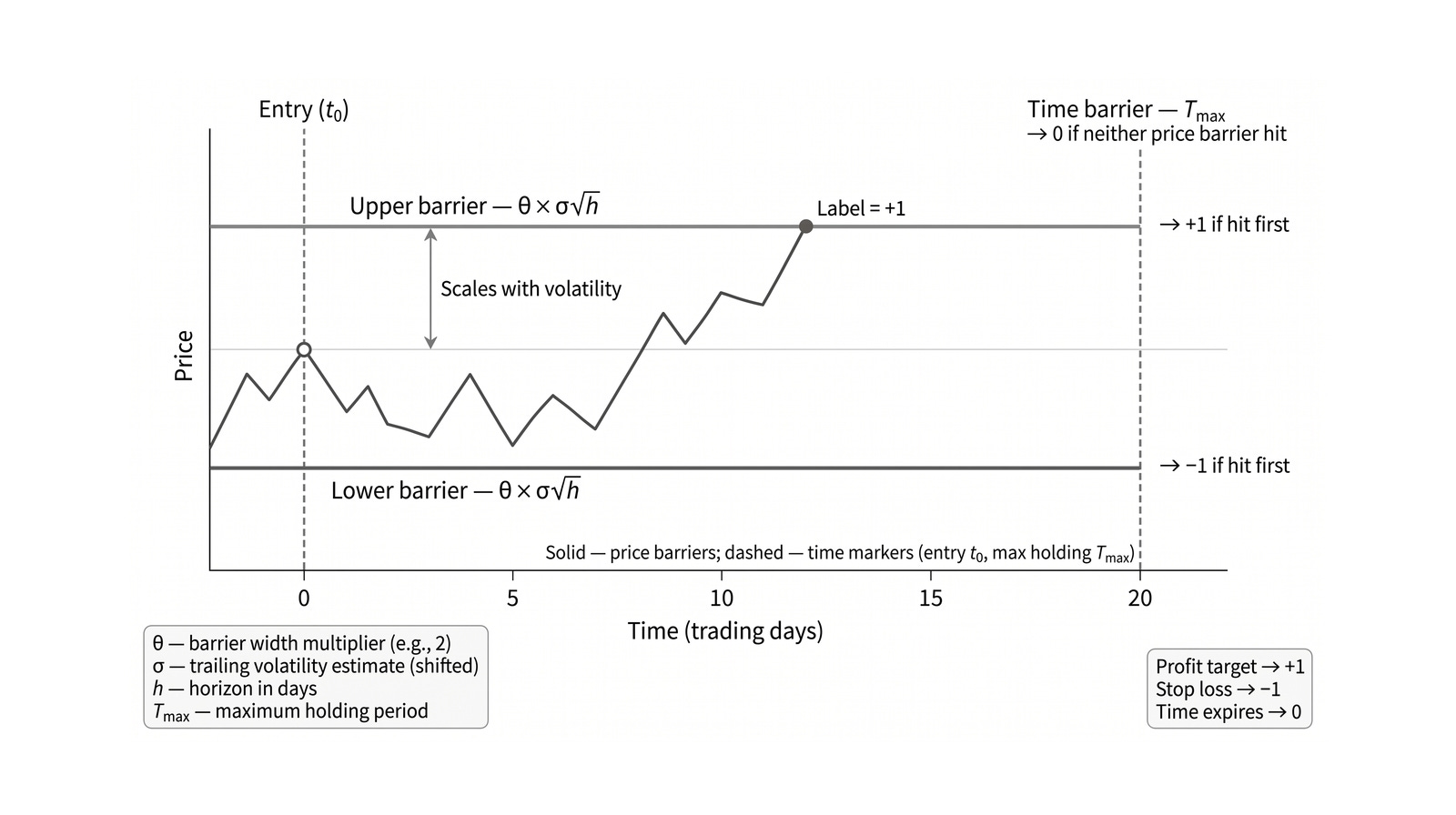
Chapter 7 uses the triple-barrier method to label an event by whichever barrier is hit first: the profit target, the stop-loss, or the maximum holding period.
The useful move is that labels are treated as trading decisions, not just target columns. Horizon, overlap, resolution time, and implied trading intensity all contribute to the target definition.
Notebook highlights:
01_data_quality_diagnosticschecks the ML4T datasets for index integrity, missing values, duplicates, outliers, and temporal gaps.02_preprocessing_pipelineimplements split-aware preprocessing, including aSplitAwarePreprocessormethod that fits scalers and encoders on training data only.03_label_methodsimplements fixed-horizon, percentile, triple-barrier, ATR-based, trend-scanning, meta-label, and sequential-bootstrap labels on ETF data.05_signal_evaluationand06_ic_inferenceuse Information Coefficients, quantile returns, signal decay, HAC standard errors, and block bootstrap to evaluate single-factor signals.07_multiple_testingcovers factor-zoo selection bias, Benjamini-Hochberg FDR control, complexity-aware corrections, the Deflated Sharpe Ratio, and the Probability of Backtest Overfitting.08_causal_sanity_checksuses timing placebos, shared-driver checks, and VIX regime heterogeneity tests to ask whether a signal story survives basic falsification.10_ml4t_library_ecosystemshows theml4t-data,ml4t-engineer, andml4t-diagnosticlibraries used across Chapters 7-12.
Chapter 8: Financial Feature Engineering
Chapter 8 moves from a trading idea to a documented feature specification: what the feature is supposed to capture, which horizon it belongs to, which reference frame it uses, and how it should be lagged.
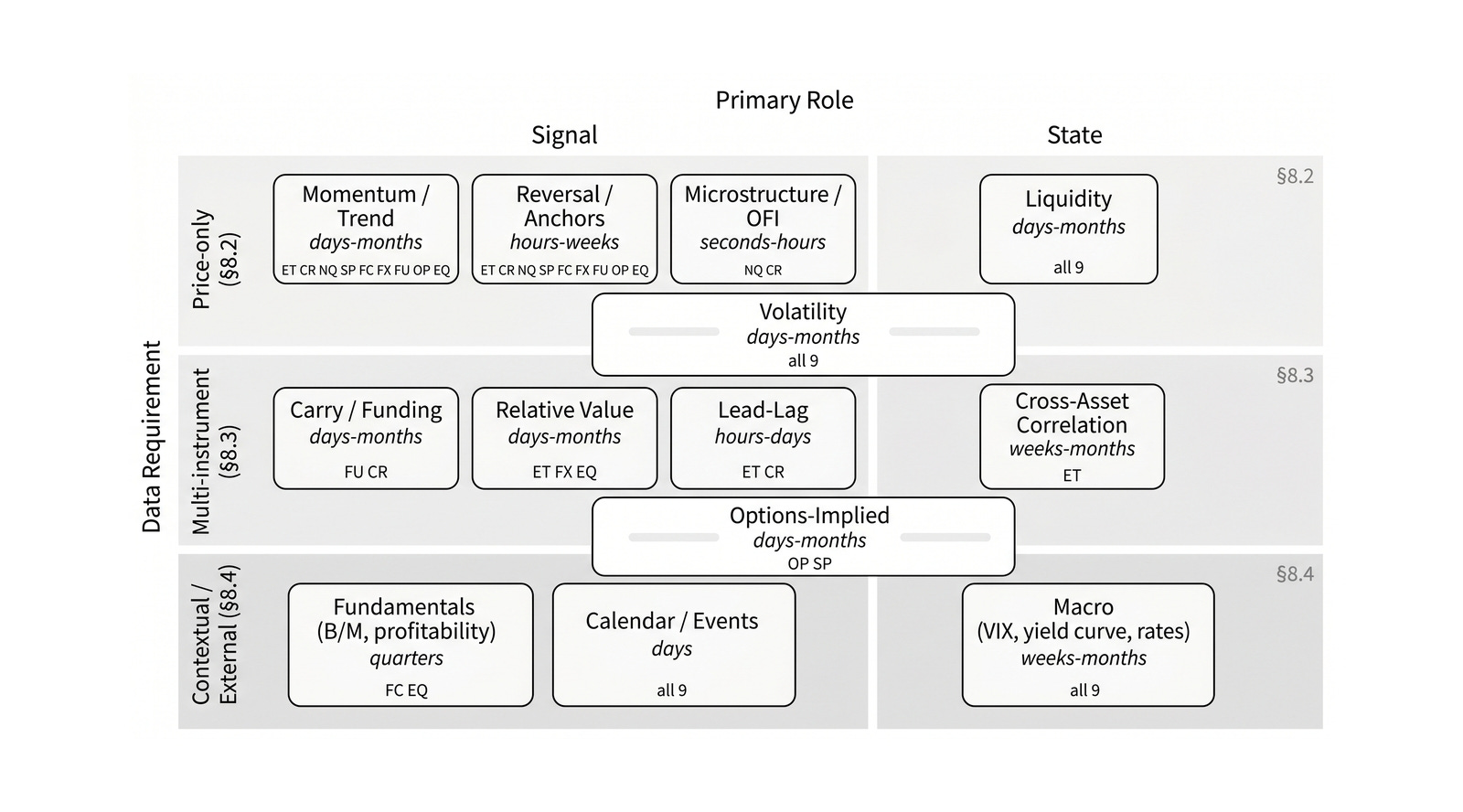
Chapter 8 organizes feature families by data requirement and role: direct signals, state variables, feasibility inputs, and context.
The chapter builds direct financial features from prices, volume, liquidity, microstructure, term structure, cross-asset relationships, options markets, fundamentals, macro data, calendars, and events. It also includes feature selection and sensitivity checks, so it is not just a catalog of indicators.
Notebook highlights:
01_price_volume_featuresbuilds multi-horizon returns, trend features, volatility estimators, volume-liquidity features, ranks, and z-scores from ETF data.02_microstructure_featurescomputes Kyle lambda, Amihud illiquidity, Roll spread, and order-flow imbalance from NASDAQ ITCH data.03_structural_cross_instrument_featuresbuilds carry and roll-yield features from CME futures, rolling beta and lead-lag features from ETFs, and options-implied features from S&P 500 options.04_fundamentals_macro_calendarbuilds value, quality, and growth features from point-in-time financial statements, plus yield-curve, credit-spread, VIX, and calendar features.05_feature_selectionreduces a large ETF feature set using IC ranking, correlation deduplication, hierarchical clustering, BH-FDR filtering, bootstrap stability, and LightGBM importance.06_robustness_sensitivitysweeps momentum parameters, checks IC by VIX regime, and builds signal-times-state interaction features.07_event_studiesimplements event studies around ETF momentum breakouts, including normal-return estimation and CAAR confidence bands.case_study_feature_summarycompares feature results across case studies, including IC distributions, FDR survival rates, and feature-family effectiveness by asset class.
Chapter 9: Model-Based Feature Extraction
Chapter 9 turns fitted models into features. These are not the final supervised models being compared later. They are inputs: filtered states, residuals, volatility estimates, uncertainty summaries, regime probabilities, and panel-level relationships.
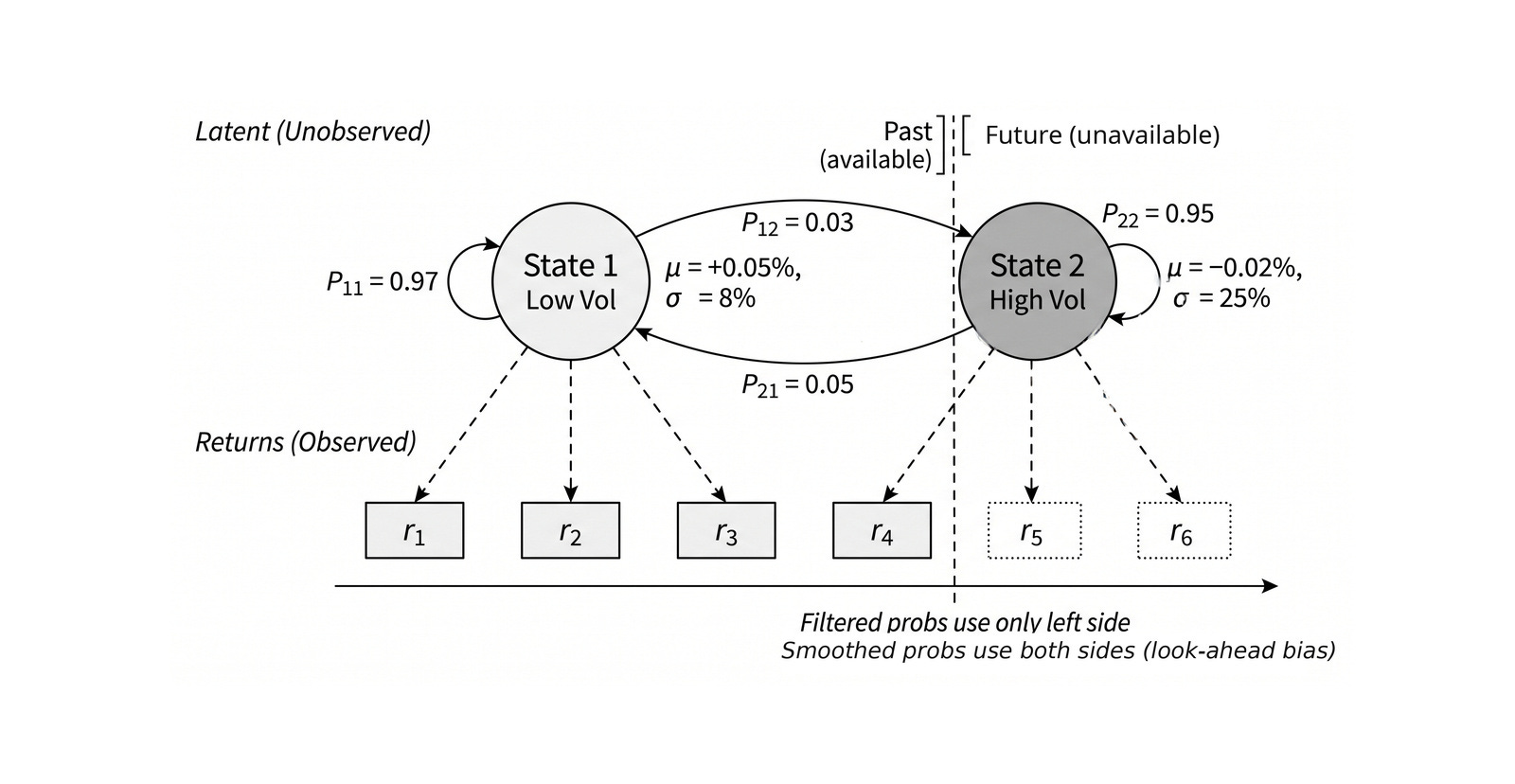
Chapter 9 turns fitted models into features, including filtered regime probabilities from Hidden Markov Models without using future observations.
A fitted model can compress structure that raw rolling features miss: latent state, changing volatility, structural breaks, uncertainty, cycles, and pairwise relationships. The point-in-time distinction matters here: filtered regime probabilities use only information available up to the decision time, whereas smoothed probabilities incorporate future observations and would leak.
Notebook highlights:
01_visual_diagnostics,02_structural_breaks, and03_fractional_differencingcover stationarity tests, ACF/PACF analysis, rolling diagnostics, break detection, and fixed-width fractional differencing.04_kalman_filterextracts level, slope, innovation, and uncertainty features, and estimates time-varying hedge ratios for pairs trading.05_spectral_featuresuses wavelets, rolling FFT features, Welch power spectral density, and spectral heatmaps.07_arima_features,08_garch_volatility, and09_har_rough_volatilityturn time-series models into residual, forecast, uncertainty, conditional volatility, persistence, leverage, and rough volatility features.10_uncertainty_featuresuses PyMC stochastic-volatility models and ARIMA forecast uncertainty to build uncertainty inputs.11_hmm_regimes,12_wasserstein_regimes, and13_regime_as_featurecompare parametric and distribution-based regime features, including the difference between filtered and smoothed probabilities.14_panel_featuresbuilds cointegration, Kalman hedge ratio, Ornstein-Uhlenbeck half-life, ranking, sector-relative, and universe aggregation features.case_study_temporal_summarycompares model-based feature inventories and incremental IC contributions across case studies.
Chapter 10: Text Feature Engineering
Chapter 10 treats financial NLP as feature engineering. It starts with lexicons, bag-of-words, TF-IDF, and static embeddings, then moves through sequential models, Transformers, domain adaptation, fine-tuning, and text-derived trading signals.
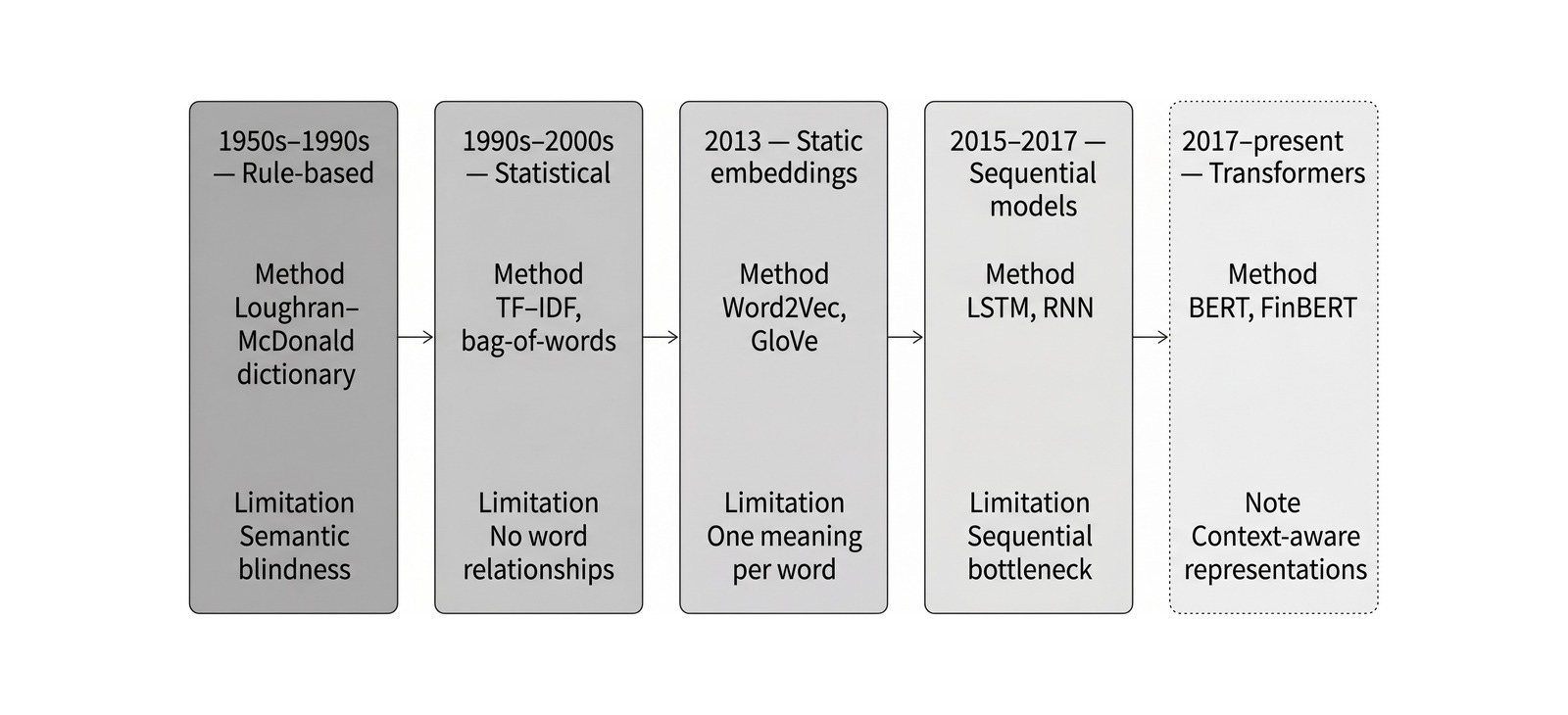
Chapter 10 moves from dictionaries and bag-of-words to contextual Transformer representations such as BERT and FinBERT.
The practical focus is timestamp-safe text features: when the text was available, which entity or asset it maps to, how the signal is aggregated, and how it is evaluated against future returns.
Notebook highlights:
01_word2vec_trainingtrains Word2Vec on Financial PhraseBank text and evaluates embeddings with similarity, analogies, and t-SNE.02_asset_embeddingsapplies Word2Vec to SEC 13F holdings, treating portfolios as sentences and stocks as words.03_sentiment_evolutioncompares TF-IDF, GloVe, and FinBERT on Financial PhraseBank and shows why distribution shift matters.04_bert_finetuningfine-tunes FinBERT, DeBERTa-v3, and ModernBERT for financial sentiment classification.05_financial_ner_finetuningfine-tunes a FinBERT-based named-entity recognizer for companies, amounts, and dates.07_news_return_signalsbuilds news surprise and sentiment factors from FNSPID news and evaluates them against S&P 500 forward returns.08_text_feature_evaluationevaluates text-derived alpha signals with IC, ICIR, t-statistics, and quintile spreads across 1-day, 5-day, and 20-day horizons.09_filing_text_signalsbuilds 10-Q MD&A sentiment and narrative-change signals and joins them to S&P 500 returns with point-in-time alignment.
These notebooks prepare research inputs and diagnostics. They do not claim that a feature survives full strategy simulation, transaction costs, portfolio construction, risk controls, or live deployment; those checks come in later releases.
Learn the workflow live
The full live-course and workshop schedule is on the ML4T courses page.
The Machine Learning for Trading: From Research to Production course starts Monday, July 6. The course uses the same workflow in live work: start with a strategy idea, build a baseline, diagnose what failed, and decide what to try next without quietly reusing the holdout.
The repository gives you the code. The course adds review and pace.
You can watch or star the ML4T repository to follow the staged release. The next releases move into model comparison, simulation, portfolio construction, transaction costs, risk, and live deployment.