

How to build a Multi-Agent Forecasting System
They can turn current unstructured evidence into scorable probabilities, but the output has to compete with a model, market, or human baseline.

Most forecasting work in ML4T starts with structured data.
A panel of returns. A table of fundamentals. A calendar of releases. A cross-section of firm characteristics. A feature matrix that tries to preserve what the model could have known at the decision time.
That remains the center of gravity. The third edition still treats data design, labels, baselines, backtests, costs, and monitoring as the hard parts of the workflow. Forecasting agents add an evidence-processing layer to that workflow.
The layer is specific: it can process current unstructured evidence on the fly and turn the result into a structured forecast artifact.
For finance, that evidence might be a central bank statement, company guidance, a filing, a research note, macro commentary, or market chatter that has not yet become a stable feature history. For sports, it might be squad news, injuries, lineup changes, travel, form, or match reports. The domains differ. The pattern is the same: some relevant information arrives as text, search results, or messy context before it arrives as a clean panel.
This Saturday, June 27, we are building this pattern in a live Maven workshop: Building Multi-Agent Forecasting Systems. The workshop uses an AIA-style multi-agent forecaster inspired by Bridgewater AIA Labs: research agents gather evidence; an aggregation layer combines their probabilities; a supervisor checks the result; calibration adjusts the final number; and every run is stored so it can be scored later.
The system should read evidence that a conventional model may miss, produce a probability, and then have that probability compete with a baseline.
The missing input is often not another price series
In a clean modeling setup, the training panel defines the world. If the feature is not in the panel, the model cannot use it. That discipline is important because it prevents hindsight from leaking into the experiment.
But real decisions often happen before the relevant information has been converted into a feature. A company may update guidance, a regulator may change tone, a central bank may revise its language, or a prediction market may move before the event has resolved. Some of that evidence would be hard to reconstruct across twenty years of history.
The same issue appears outside finance. In the World Cup forecaster, a statistical model can estimate the probabilities of a win, draw, or loss from historical match data. Match-specific information is a different kind of input: squad updates, recent form narratives, injury reports, expected lineups, conditions, and tournament context.
An agent can put that evidence into the workflow without pretending it has already become a clean historical feature.
The agent can search, read, summarize, compare sources, reason over contradictions, and emit a probability with a trace of what it used. That output is not automatically correct. It is a candidate input.
The test is whether the candidate input improves the forecast record, the diagnosis, or the decision process when compared with a baseline.
Web search is the easy version
The simplest forecasting agent uses a web search.
Give the agent a binary question, a cutoff date, a search tool, and a prompt that asks for evidence, uncertainty, and a probability. Let several agents search independently. Aggregate their probabilities. Ask a supervisor to check the disagreement. Store the trace. Score the result when the event resolves.
That already teaches most of the system design: resolvable questions, cutoff-aware retrieval, source metadata, schema-bound outputs, aggregation policy, calibration, and baseline scoring.
The current search is convenient but not replayable. Search rankings change. Pages move. Articles update. Snippets may reflect information unavailable as of the forecast date. Date filters help, but they do not create a clean historical archive. If you want to tune the system rather than merely demo it, a point-in-time evidence archive becomes much more attractive.
For finance, that might mean timestamped news, filings, transcripts, macro releases, prediction-market snapshots, and internal research notes. For sports, it might mean dated match previews, squad announcements, injury updates, odds, and official lineups. The important feature is not that all of this is text. It is that the system can know what was available at the time.
Once the evidence is archived point-in-time, the agent becomes easier to improve:
You can backtest retrieval policies without letting the agent read the future;
You can compare prompts, tools, and agent counts on the same historical evidence;
You can run prompt or program optimization against resolved outcomes;
You can measure whether a supervisor helps or merely adds cost;
You can decide whether debate improves calibration or only produces longer traces.
A live demo can run on the current search. A system that improves over time needs evidence that it can replay.
Two practical ways to use the forecast
Two deployment patterns cover most practical use cases.
The first is to build the agent in isolation as an additional forecast. It reads evidence, produces a probability, and gets compared with a market price, a statistical baseline, or a human forecast. If it provides incremental information, the output can be ensembled with the baseline or used as a feature in a downstream model.
That is the restrained interpretation of the AIA Forecaster result. On ForecastBench, the report finds that performance is statistically indistinguishable from that of human superforecasters. On MarketLiquid, the paper evaluates 322 liquid prediction-market questions at five forecast dates each, producing 1,610 forecast instances from April 2 to May 23, 2025. The agent alone trails the market consensus there. The practical result is that combining the agent forecast with market consensus beats either source alone on that benchmark.
That is a realistic role: independent, inspectable evidence processing that can add information when combined with a strong baseline.
The second pattern is to enrich the agent with structured inputs from the start. It receives a model prior, market odds, recent structured data, and the current evidence it should inspect.
That is what we are doing in the World Cup agent: model the prior first, current evidence second, and a separate forecast surface throughout.
The World Cup app illustrates this second pattern. A Poisson-style team-strength model provides the prior; the agent reads the current football context and publishes its own win/draw/loss forecast alongside the model. In one pre-match validation run, changing the prompt increased the agent’s mean maximum swing from the model by 3.5 percentage points across eight group-opener fixtures. The goal was to keep the model prior visible while allowing the agent to move when supplied evidence justified it.
If the agent simply rubber-stamps the model, it adds little. If it makes large moves without evidence, it adds noise. Evidence-driven deviations are the cases to track and evaluate.
The AIA-style architecture
Chapter 24 of Machine Learning for Trading uses forecasting because the output can be scored. A forecast has a timestamp, a probability, a resolution rule, and an eventual outcome.
For prediction-market questions, the target is usually a binary event. For match forecasts, the outcomes are mutually exclusive. The architecture is similar, but the scoring layer changes.
The architecture we use in the workshop follows the same practical sequence:
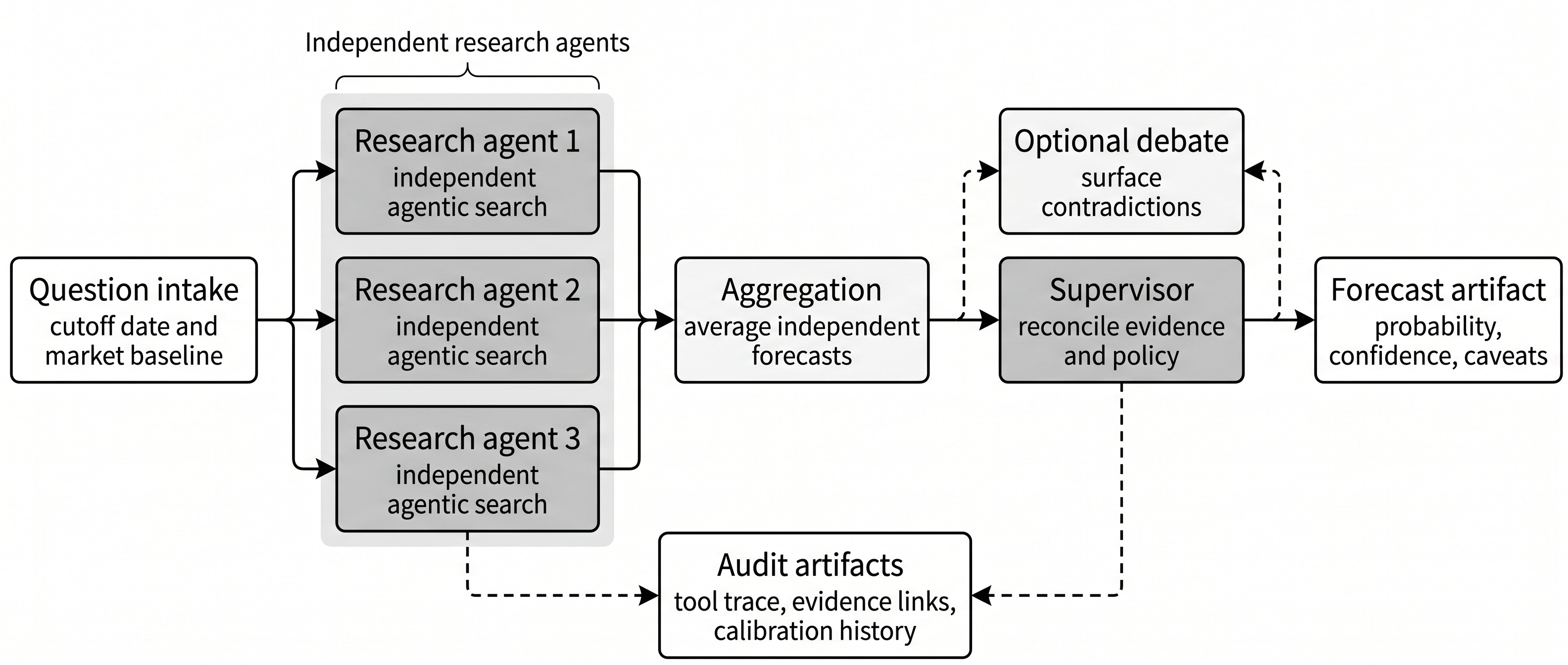
An AIA-style forecasting system turns a question into research-agent traces, an aggregate forecast, supervisor review, calibration, and a persisted probability that can be scored later.
Define the forecast target and cutoff policy.
Run several research agents that search and reason independently under the same cutoff policy.
Aggregate their probabilities under an explicit rule.
Optionally run a debate or specialist review stage when the question set warrants the cost.
Let a supervisor inspect disagreements and perform clarifying searches when needed.
Calibrate the final probability.
Persist the run: question, inputs, traces, configuration, token usage, probabilities, and later scores.
This is a read-only forecasting system. It can pull questions, prices, search results, and evidence. It does not place trades or bets.
That boundary makes the system easier to evaluate. A read-only agent can be wrong without also creating an execution problem. The first product of the system is a probability and a record. Action comes later, if the probability survives comparison with the rest of the workflow.
What has to be measured
Forecasting agents invite a familiar mistake: treating a good explanation as evidence of a good forecast.
The explanation may be useful. It may help diagnose what the system saw. It may reveal a stale source, a missing counterargument, or a brittle prompt. But the forecast has to be judged by scoring rules and baselines.
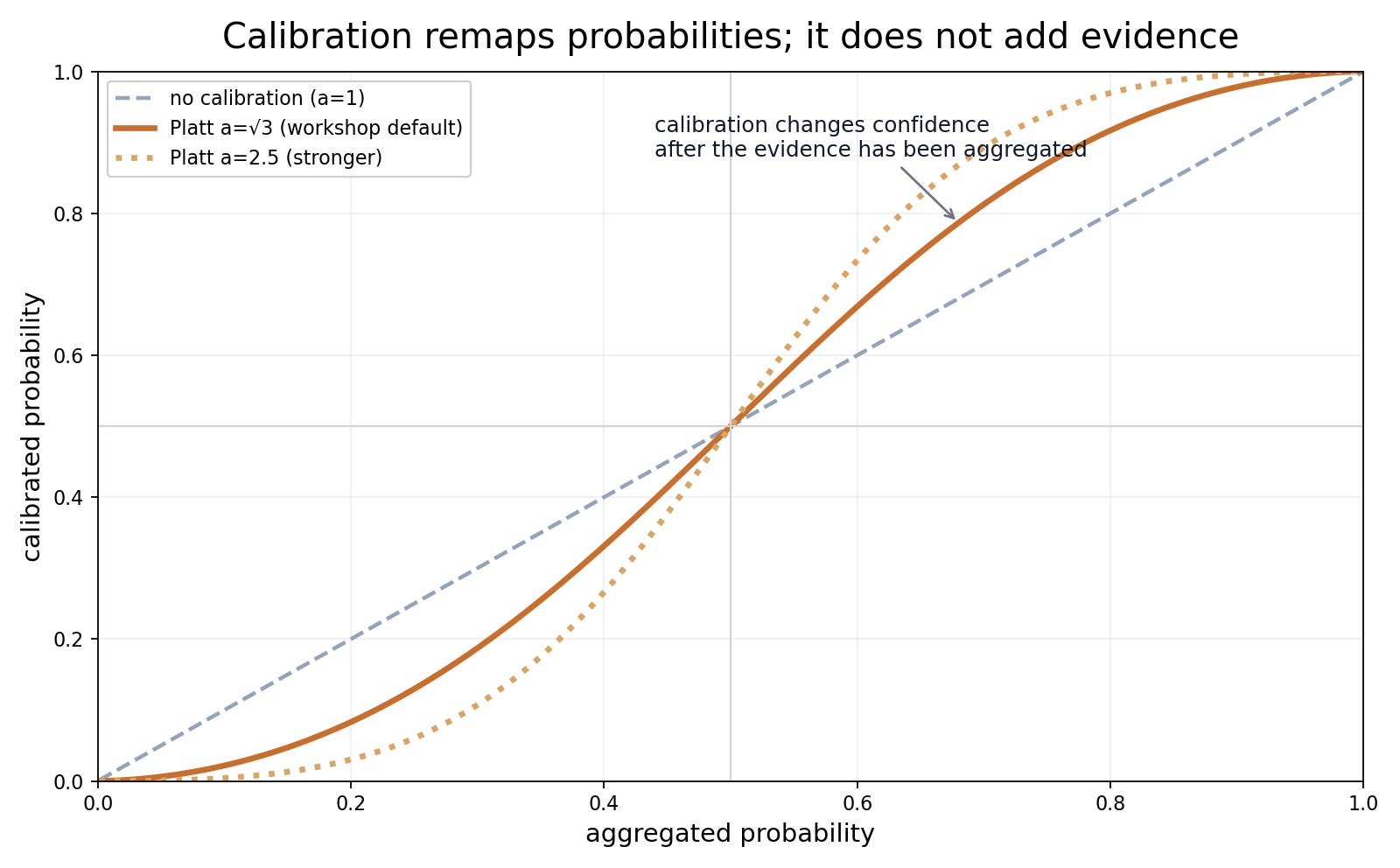
Calibration remaps probabilities based on past forecast errors. It cannot add evidence the agent missed, and it should be evaluated on a disjoint set of resolved forecasts.
At a minimum, the evaluation should ask:
Does the agent improve Brier score, log score, calibration, or sharpness relative to the baseline?
Does the improvement survive time-disjoint evaluation?
Does the agent add information when combined with market consensus or a statistical model?
Which component actually helps: search, more agents, debate, supervisor, calibration, or a better evidence archive?
Does the benefit justify the cost and latency?
A negative result still tells you which component not to keep. An agent may fail to beat a baseline on its own and still improve an ensemble or help diagnose model blind spots. If it only produces plausible prose, it should not survive the ablation.
This is also why point-in-time evidence matters. Without it, a backtest can become a story about leakage. With it, the same architecture can become a repeatable experiment: the same question, the same cutoff, the same archive, different prompt or tool policy, scored after resolution.
What we will build on Saturday
The workshop is built around a working AIA-style forecaster.
Students run a CLI and dashboard, inspect individual agent traces, change profiles, compare single-agent and multi-agent runs, look at aggregation and calibration, and see how forecast runs are stored for later scoring. The deterministic replay path works without API keys. Live model and search providers are optional upgrades.
The day is deliberately practical:
start from a resolvable question;
run one research agent and inspect its evidence trail;
move from one agent to several;
aggregate and calibrate the probabilities;
store the run so it can be evaluated later;
discuss how the same pattern generalizes from prediction markets to finance, sports, and other decision workflows.
The ML4T link is the evaluation habit: preserve the timestamp, compare with a baseline, and remove components that do not improve the record. Forecasting agents make a new class of inputs available to that workflow.
The live workshop is this Saturday: Building Multi-Agent Forecasting Systems.
The free Lightning Lesson page is here: Build Multi-Agent Systems You Can Audit.
In the workshop, a component earns its place only if the stored runs show that it improves the forecast record, the diagnosis, or the evaluation against the baseline.