

AI Agents in Finance: A Reading List
What to read before building read-only financial agents that retrieve evidence, use tools, make forecasts, and leave audit trails.

The well-known Sutskever/Carmack reading list worked because it did not try to be an encyclopedia. It gave readers a path: learn these ideas, and a large part of modern deep learning becomes easier to understand.
This issue uses the same format for a narrower question: what should you read before building AI agents for financial research and forecasting?
The answer is not a list of agent frameworks or orchestration libraries. It starts earlier. Core agent design still involves search under limited computation, action under partial observation, tool validity, state, delegation, evaluation, and human supervision. Language models changed the substrate, but not the underlying control problem.
Chapter 24 of Machine Learning for Trading implements that view. It builds read-only research and forecasting agents that gather evidence, call tools, maintain state, produce probabilities, and leave artifacts that can be replayed, scored, and audited. More specifically, the chapter shows how to build the Bridgewater AIA Forecasting Agent through to live deployment.
You can also learn how to build this in our new workshop on Building Multi-Agent Forecasting Systems, which teaches how to engineer this particular agent harness and loop in one day.
In the chapter, an agent does not place trades. It calls market data APIs, searches for filings and news, retrieves documents, runs calculations, writes structured forecasts, and records what happened. The question is not whether a chatbot can sound like an analyst. The question is whether a workflow can produce useful decision-support artifacts that can be replayed, scored, and governed.
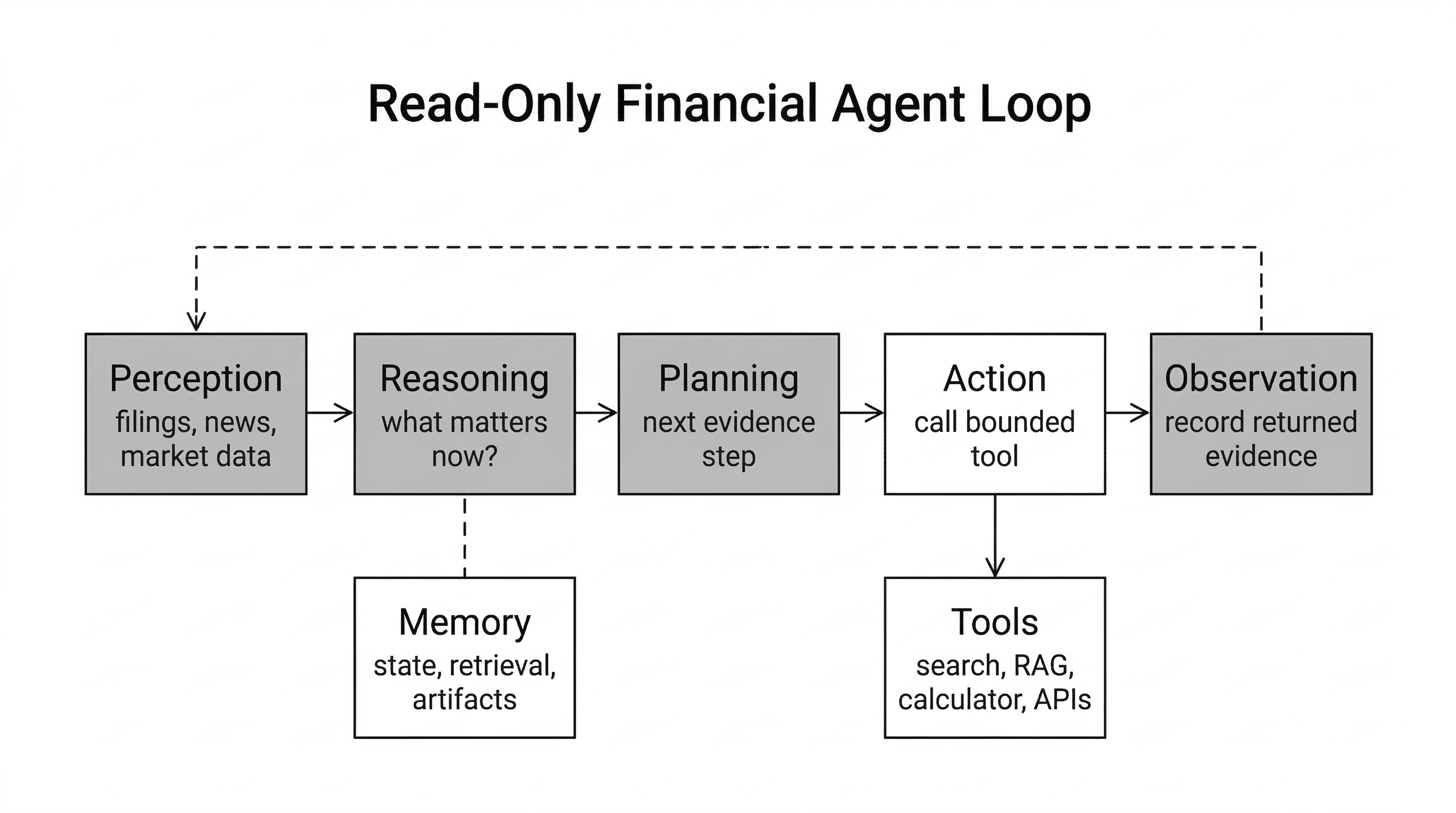
Figure 1. Chapter 24 treats financial agents as read-only workflows over evidence, tools, memory, and audit artifacts. Order generation and execution require a separate layer of permissions, risk, and controls.
What finance changes
Finance turns a generic agent problem into a time-sensitive evidence problem. The system has to know what was knowable when, where a number came from, which tool produced it, and whether the evidence was available before the forecast or backtest decision.
Five constraints shape the reading path:
Time. Filings, prices, macro releases, transcripts, and news have timestamps. An agent must preserve cutoffs rather than mix past and future evidence.
Provenance. Financial evidence is not interchangeable text. A model summary, an SEC filing, an exchange quote, and a scraped article carry different reliability and permission properties.
Leakage. Evaluation can be contaminated by training data, revised data, benchmark overfitting, or hidden access to answers. Finance makes this more dangerous because small information leaks can appear to be forecasting skill.
Calibration. Many outputs are probabilities, not prose. The evaluation question is not only whether the explanation sounds plausible, but whether the forecast is calibrated after resolution.
Capital-at-risk boundaries. Research support, portfolio recommendation, order generation, and execution are different system classes. Chapter 24 stays on the research-support side of that boundary.
A core path for the long weekend
Start with these core entries:
Kaelbling, Littman, and Cassandra on POMDPs: financial agents act from belief states, not complete market state.
Rao and Georgeff on BDI agents: beliefs, goals, intentions, and resource-bounded deliberation predate LLM wrappers.
Horvitz on mixed-initiative interfaces: agents need rules for proceeding, asking, abstaining, and escalating.
Lewis et al. on retrieval-augmented generation: finance needs external, updateable, provenance-bearing knowledge.
WebGPT: an early template for search, evidence collection, citation, and answer generation in one loop.
MRKL Systems: language models can route to tools, calculators, retrieval systems, and symbolic modules instead of internalizing every operation.
ReAct: reason-act-observe is a canonical starting pattern for evidence-grounded agents.
CodeAct: executable actions fit technical research workflows better than unconstrained prose.
AI Agents That Matter: agent evaluation has to include cost, reproducibility, holdouts, and benchmark overfitting.
AgentDojo and the OWASP Top 10 for LLM Applications 2025: retrieved content and tool access create security problems that ordinary model benchmarks miss.
ForecastBench and Halawi et al. on language-model forecasting: financial agents need leakage-aware forecasting evaluation, not just impressive rationales.
AIA Forecaster, Finance Agent Benchmark, and FinToolBench: together they show where agentic financial research works now and where the evidence remains thin.
The rest of the issue gives the broader route. It is organized by design problem rather than by publication date.
The list deliberately excludes most framework documentation, product announcements, and “autonomous trading bot” papers. Frameworks matter in implementation, but they age quickly. The reading path below focuses on more durable design problems: state, tools, retrieval, partial observation, supervision, evaluation, security, forecasting, and governance. Execution agents and order-routing systems are also out of scope, as Chapter 24 remains on the research-support side of the capital-at-risk boundary.
The old problems are still the hard problems
Newell and Simon, Human Problem Solving. Newell and Simon frame intelligence as search through a structured problem space under bounded computation. That framing keeps the central object in view: not a fluent answer, but a process that moves through possible states, operators, and goals.
Hart, Nilsson, and Raphael, “A Formal Basis for the Heuristic Determination of Minimum Cost Paths”. The A-star paper makes a point that still holds: search quality depends on how the system allocates its limited computational budget. LLM agents do not escape that constraint. They move it into prompt length, tool calls, branching, reranking, and supervisor passes.
Rao and Georgeff, “BDI Agents: From Theory to Practice”. BDI gives the literal pre-LLM agent vocabulary: beliefs, desires, and intentions. The vocabulary is older; the design problem remains current. A financial research agent needs a representation of what it believes, what it is trying to answer, which plan it is executing, when to reconsider, and what state must survive between steps.
Kaelbling, Littman, and Cassandra, “Planning and Acting in Partially Observable Stochastic Domains”. Partial observability is central in finance. The agent never sees the full state of the market, the company, or the policy process. It sees filings, quotes, transcripts, news, and partial indicators. The paper makes explicit that agents act from belief states, not from truth.
Sutton, Precup, and Singh, “Between MDPs and Semi-MDPs: A Framework for Temporal Abstraction in Reinforcement Learning”. The options framework gives a theory of temporally extended actions. Modern systems call them tools, skills, routines, subagents, or workflows. The abstraction problem is the same: when should a multi-step behavior be treated as a single action, and which state must be preserved before and after it runs?
Erman, Hayes-Roth, Lesser, and Reddy, “The Hearsay-II Speech-Understanding System”. Hearsay-II is the classic blackboard architecture: specialized components coordinate through a shared workspace. That pattern keeps returning in planner-executor-reviewer loops, multi-agent debate, research-agent ensembles, and supervisor reconciliation. The same architecture helps explain Chapter 24’s forecasting pipeline.
Sheridan, Telerobotics, Automation, and Supervisory Control. Sheridan treats autonomy as a control relationship rather than a marketing label. The practical questions are who monitors execution, when control is handed back, and what the human is expected to approve. Those questions apply directly when an agent’s output can influence capital allocation, research priorities, or a published forecast.
Horvitz, “Principles of Mixed-Initiative User Interfaces”. Mixed initiative gives a concrete frame for human-agent work. A financial agent needs rules for when to proceed, when to ask for clarification, when to abstain, and when to escalate. This is not only a user-interface problem. It is part of the risk-control surface.
The LLM-era primitives
Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”. Chain-of-thought showed that eliciting intermediate reasoning can improve multi-step performance. Chapter 24 treats this as a control surface rather than an audit record. In financial agents, the auditable objects are tool calls, observations, state transitions, evidence records, prompts, model versions, policies, and scored outputs. Free-form reasoning text is not enough.
Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. RAG is not an agent paper, but finance agents are retrieval-bound. The distinction between parametric memory and external, updateable, provenance-bearing knowledge matters for filings, transcripts, news, research notes, macro releases, and market data.
Nakano et al., “WebGPT: Browser-Assisted Question-Answering with Human Feedback”. WebGPT is an early modern template for a language model that searches, collects evidence, cites sources, and answers with the browser in the loop. For finance, this is the move from static model output to evidence acquisition. The model is no longer only producing text. It is choosing what evidence to retrieve before it answers.
Karpas et al., “MRKL Systems”. MRKL made modularity explicit. The language model routes among tools, symbolic modules, knowledge sources, and external calculators. Chapter 24 uses the same principle in a finance setting: deterministic calculations should be tools, retrieval should carry provenance, and the LLM should not pretend to internalize every operation.
Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models”. ReAct is a canonical starting pattern for evidence-grounded agents: reason, act, observe, repeat. In Chapter 24, the first notebook builds this loop with structured JSON decisions and trace capture. The trace ties stated reasoning to tool calls and observations. The hard audit evidence still consists of the tool invocation, observation, state transition, and stored source.
Yao et al., “Tree of Thoughts: Deliberate Problem Solving with Large Language Models” and Shinn et al., “Reflexion: Language Agents with Verbal Reinforcement Learning”. Tree of Thoughts adds branching and scoring at decision points where premature commitment is costly. Reflexion records post-run lessons that can persist without updating model weights. In finance, both mechanisms need controls. A branch can help compare market hypotheses, and a lesson can improve future behavior. But both need validity horizons, provenance, and pruning rules. Otherwise, a temporary market condition becomes a persistent bias.
Wang et al., “Voyager: An Open-Ended Embodied Agent with Large Language Models”. Voyager is not a finance paper, but its skill-library idea maps well to research agents. A financial operator should not have to rediscover the same data-loading, feature-inspection, or backtest-diagnostic procedures every time. It needs a bounded skill corpus whose behavior can be inspected.
Wang et al., “Executable Code Actions Elicit Better LLM Agents”. CodeAct reframes action as executable code rather than fixed text or JSON. Technical research workflows involve many computational actions: querying a registry, reading a parquet file, computing an IC, running a backtest, or inspecting a result table. Chapter 24’s research operator follows this direction by providing the model with general tools and a skill corpus.
Yang et al., “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering”. SWE-agent made the agent-computer interface a first-class variable. That lesson generalizes beyond software engineering. If the environment is hard to inspect, the state is hidden, the tools are poorly named, or errors are hard to recover from, the agent will fail due to interface issues even when the base model is strong.
Evaluation and security are part of the system
Kapoor et al., “AI Agents That Matter”. This paper anchors the evaluation section. It argues that accuracy alone is the wrong target because cost, reproducibility, holdout design, benchmark overfitting, and the needs of downstream developers decide whether an agent works in practice. Finance needs that discipline.
AgentBench, WebArena, OSWorld, and SWE-bench. These benchmarks shifted evaluation from “does the model produce the right text?” to “can the system change an environment into the target state?” That shift fits agent evaluation, but it also creates new validity problems. An agent can satisfy a checker without doing the intended work, reading the hidden state, or exploiting the evaluation harness itself.
AgentDojo. AgentDojo turns indirect prompt injection into an environment problem. The agent must complete assigned work while treating retrieved content as untrusted. That model fits finance, where retrieved documents can contain adversarial instructions, speculative narratives, stale facts, or conflicting claims.
OWASP Top 10 for LLM Applications 2025. OWASP is not an agent paper, but tool-connected LLM systems create security failures that ordinary model evaluation misses. Chapter 24 turns this into engineering controls: least privilege, source allowlists, prompt-injection filters, policy proxies, and logged allow/deny decisions.
Two papers from May 2026 are recent stress tests, not settled references. Evaluating Deep Research Agents on Expert Consulting Work assesses deep-research agents on structured analytical deliverables, using verifiers, rubrics, and cognitive traps. Reported acceptance rates are low across frontier systems. SaaSBench tests long-horizon work in multi-component enterprise software and finds that many failures occur during setup, configuration, and integration before deep business logic is reached. The finance lesson is direct: agent failures are often system failures, not only reasoning failures.
The finance branch
The finance literature below falls into four groups: broad LLM-in-finance maps, financial-agent benchmarks, forecasting-agent systems, and portfolio or trading-agent architectures. Those are not the same system class. A research benchmark, a forecasting assistant, a portfolio-construction committee, and an execution agent require different evidence and controls.
Kong et al., “Large Language Models for Financial and Investment Management”. Kong et al. provide a broad investment-management map: retrieval, domain-specific data, task decomposition, evaluation, and deployment constraints. The paper does not reduce finance to sentiment analysis or trading signals. It treats LLMs as part of a workflow that has to respect evidence, timing, and institutional constraints.
Finance Agent Benchmark. This benchmark adds a concrete constraint. It uses expert-authored financial research tasks that require recent SEC filings and an agentic harness with search and EDGAR access. The dataset has 537 questions across nine task categories. The best-reported model achieved 46.8 percent accuracy at an average cost of $3.79 per query. The evidence is concrete, costly, tool-based, and still limited.
Lu et al., “FinToolBench: Evaluating LLM Agents for Real-World Financial Tool Use”. Finance Agent Benchmark tests financial research tasks over filings and search. FinToolBench tests tool-using financial agents under runnable execution conditions. It pairs 760 executable financial tools with 295 tool-required queries and evaluates not only success, but also timeliness, intent restraint, and regulatory-domain alignment. That maps directly to Chapter 24’s view of agents as auditable workflows over tools, traces, and policy constraints.
Xie et al., “FinBen: A Holistic Financial Benchmark for Large Language Models”. FinBen is a checkpoint before discussing agents because it separates financial language tasks from numerical reasoning, forecasting, risk, and decision-making. Static benchmarks do not evaluate full agent behavior, but they reveal where base-model capabilities are thin before an agent loop adds tools, retrieval, and state.
Schoenegger et al., “AI-Augmented Predictions”. This paper serves as a bridge between general agents and forecasting. LLM assistants can improve human forecasting accuracy, but the improvement comes through a decision-support relationship, not full replacement. That is close to Chapter 24’s stance: agents gather and organize evidence, but the output still needs scoring, calibration, and supervision.
Karger et al., “ForecastBench”. ForecastBench evaluates future events whose answers are not known at submission time. That design directly targets leakage. It also keeps the evaluation unit clear: a probability on a resolvable question, not a compelling narrative about what may happen.
Halawi et al., “Approaching Human-Level Forecasting with Language Models”. Halawi et al. provide the methodological bridge to AIA Forecaster. The system searches for relevant information, generates forecasts, and aggregates predictions against human forecaster baselines. It treats forecasting agents as workflows for retrieval, aggregation, and evaluation.
Alur et al., “AIA Forecaster: Technical Report”. AIA Forecaster is the chapter’s central reference for the forecasting-agent implementation. It combines agentic search, independent forecasts, supervisor reconciliation, and statistical calibration. Its reported results cut both ways: expert-level performance on ForecastBench, weaker performance than market consensus on a harder prediction-market benchmark, and better results when combined with market consensus. That supports decision assistance, not a claim that an LLM forecasts on its own.
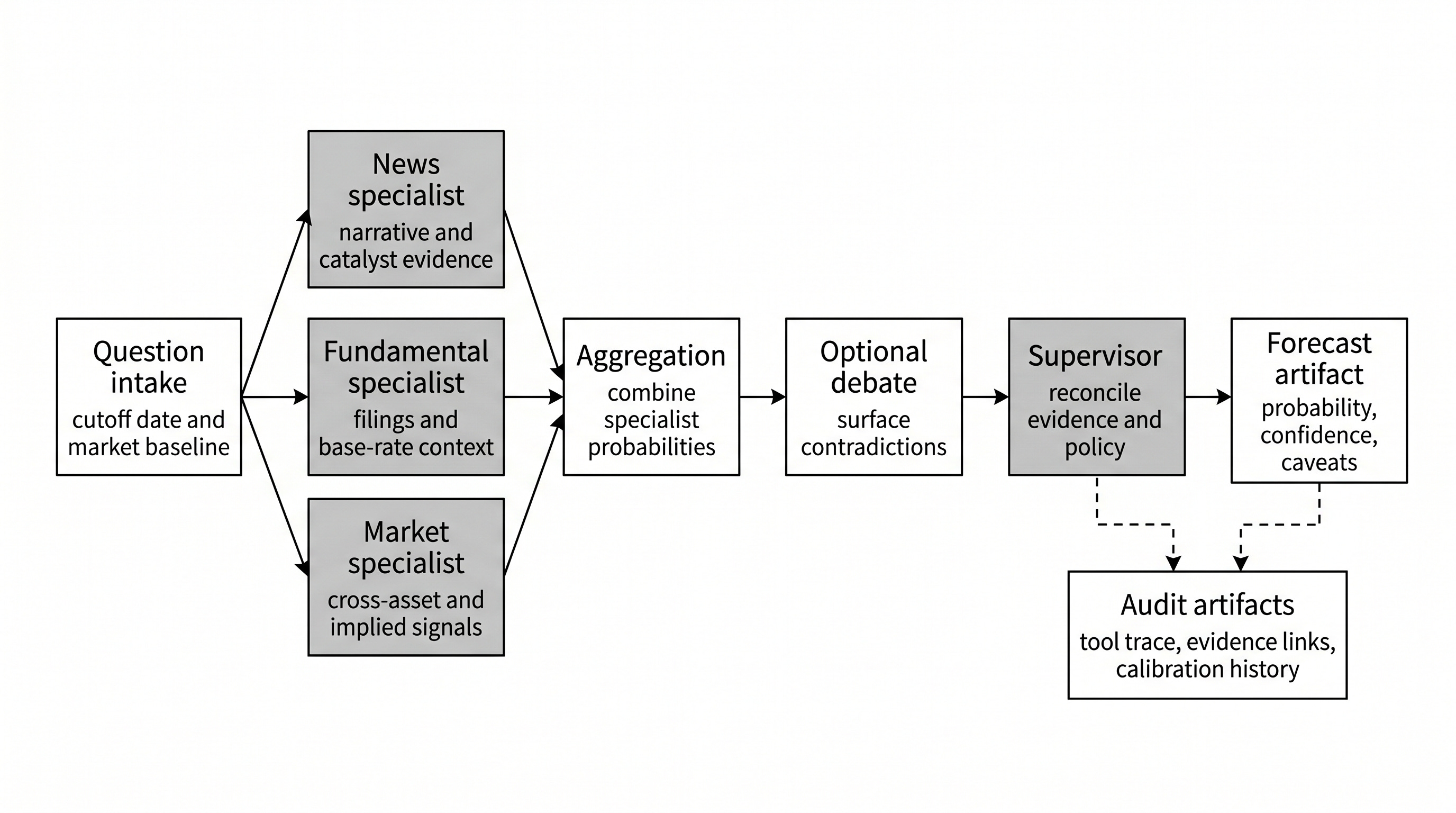
Figure 2. Chapter 24 implements forecasting as a supervised evidence workflow: specialists produce independent views, aggregation combines probabilities, debate surfaces contradictions, and the final artifact preserves probability, confidence, caveats, and audit evidence.
Yu et al., “FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design” and Yu et al., “FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement”. These papers belong on the list as design references for memory and multi-agent financial decision systems. Treat them as architecture references, not as proof of deployable trading edge. They expose a design problem: when an agent stores lessons from prior decisions, which lessons are valid enough to persist, and which should be pruned before they become bias?
Zhao et al., “AlphaAgents: Large Language Model based Multi-Agents for Equity Portfolio Constructions” and Ang, Azimbayev, and Kim, “The Self Driving Portfolio”. These papers move from research assistance toward portfolio construction. Chapter 24 reads them cautiously. Role-based analysts, peer critique, investment policy constraints, and supervisor combinations are useful architectural patterns. They do not remove the need for statistical evaluation, transaction-cost modeling, permissions, and operational controls.
Xia et al., “Agentic Trading: When LLM Agents Meet Financial Markets”. This May 2026 survey is best read as a methodological audit, not as a settled taxonomy. It maps 77 LLM-based trading-agent studies and finds that comparable evaluation remains weak: time-consistent splits, transaction-cost assumptions, universe construction, execution semantics, and reproducible artifacts are often missing. That supports Chapter 24’s conservative boundary: before financial agents influence capital, their evidence, timing, costs, and execution assumptions must be inspectable.
Fabozzi and Lopez de Prado, “Implementing AI Foundation Models in Asset Management”. This paper anchors the governance thread. Prompts, retrieval corpora, model versions, and outputs become controlled artifacts once they affect asset management decisions. That is why Chapter 24 treats traces and replay as model-risk infrastructure, not just an engineering convenience.
Lopez-Lira, Tang, and Zhu, “The Memorization Problem”. Economic forecasting with LLMs has a contamination problem: a model may appear to forecast the past because it has absorbed realized outcomes during training. That makes pre-cutoff evaluation hard to interpret. Chapter 24’s answer is not to trust narrative claims of forecasting skill. It uses cutoff dates, time-shift tests, event windows, baselines, and post-resolution scoring.
Lee et al., “Your AI, Not Your View”. Lee et al. show that LLMs can carry systematic investment preferences and confirmation bias. Retrieval and tool use do not automatically remove latent model preferences. A financial agent needs stress tests that present the same evidence under different framings and check whether the conclusion changes for the wrong reason.
can’t wait for the third edition.
The read-only boundary matters in finance. Evidence retrieval, forecasts and tool use are already risky enough before the system can trade, approve or change records. The permission class is part of the product design.