

A Coding-Agent Reading List: Behind the Loops
Loop engineering is only the surface. A reading path through the older control problems underneath — and the line between what a coding agent may change and the experimental decisions that determine whether a result is valid.

This is a sourced reading list on coding agents, split into six kinds of source — practitioner essays, control-theory foundations, LLM-agent primitives, systems and harness papers, field studies, and benchmarks — so you can match a question to the evidence that can settle it. The through-line: “loop engineering” is the visible surface; the problems underneath — bounded search, partial observability, delegation, verification — are older and better studied.
“Loop engineering” names a real shift in practice: developers spend less time on single prompts and more time designing the system around the agent — context, tools, state, branches, tests, permissions, review, and stop rules. That is worth naming.
But a serious reading list cannot stop with the current discourse. The current labels give new names to problems that control theory, planning, and human-automation research have studied for decades: bounded search, partial observability, shared state, reusable actions, delegation, verification, and supervisory control. The newer work matters because LLMs made these problems operational in software repositories, where the agent can change files and the environment can push back through tests, logs, compilers, benchmarks, diffs, and code review.
This list separates six kinds of sources:
practitioner pieces that explain why “loops” became the current label;
older control and agent foundations that give the label depth;
LLM-agent primitives that explain the mechanism;
coding-agent systems and harness papers;
empirical studies of adoption, review, refactoring, context, and test quality;
benchmarks and safety work that measure task completion or risk.
That separation matters. A benchmark is not the same as a field study. A product essay is not the same as evidence. A context-file study is not the same as a repository-level benchmark. Mixing them into one bucket makes the field look thinner than it is.
Match your question to the bucket, and note what that kind of source can and cannot settle:
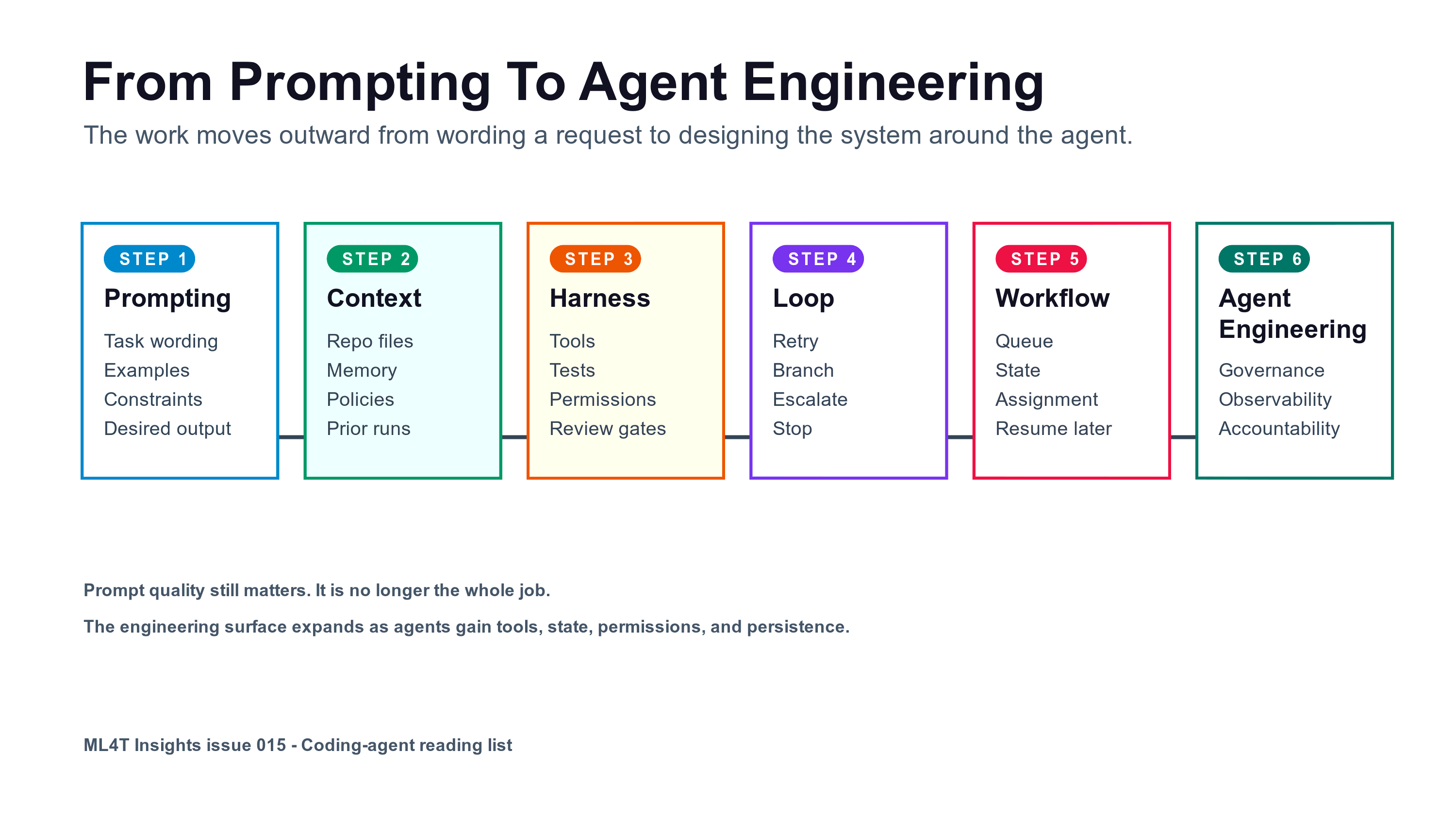
Prompt quality still matters, but the engineering surface expands as agents gain context, tools, state, permissions, verification, and persistence.
From Prompting To Loop Engineering: The Current Discourse
Read these first to understand the vocabulary. Then move on.
Addy Osmani, “Loop Engineering”. The term’s current anchor. Osmani frames loop engineering as designing the system that prompts, monitors, and resumes the agent. The useful primitives are automations, worktrees, skills, plugins or connectors, subagents, and external memory. Read it for language, not for empirical proof.
Andrew Ng on three product-building loops (The Batch #359, June 2026). The highest-profile statement of the frame, published as the naming wave crested. Ng separates three loops by timescale and who acts: an agentic coding loop (minutes), a developer-feedback loop (tens of minutes to hours), and an external-feedback loop (days to weeks). That is a different cut than Figure 2 below, which separates loops by what each one validates — evidence, not contradiction, that “loops” already names several things. Ng also traces the phrase’s spread to Boris Cherny (Claude Code) and Peter Steinberger (OpenClaw).
Armin Ronacher, “The Coming Loop”. The skeptical counterpart. Ronacher separates the model’s tool-result cycle from the external harness that restarts, redirects, or escalates work. Read it for comprehension debt: the risk that code becomes easier for machines to change than for humans to understand.
Simon Willison, “Designing agentic loops”. A cleaner earlier statement of the loop idea: agents run tools in a loop to achieve a goal. The value is that it predates the June 2026 naming wave.
Birgitta Böckeler, “Harness engineering for coding agent users”. Published on martinfowler.com. Note the pieces around the model: guides, sensors, tests, feedback, and the boundaries that make delegated work reviewable.
Geoffrey Huntley, “everything is a ralph loop”. A reminder that the external while-loop around a coding agent existed before the current name. The practice predates the label.
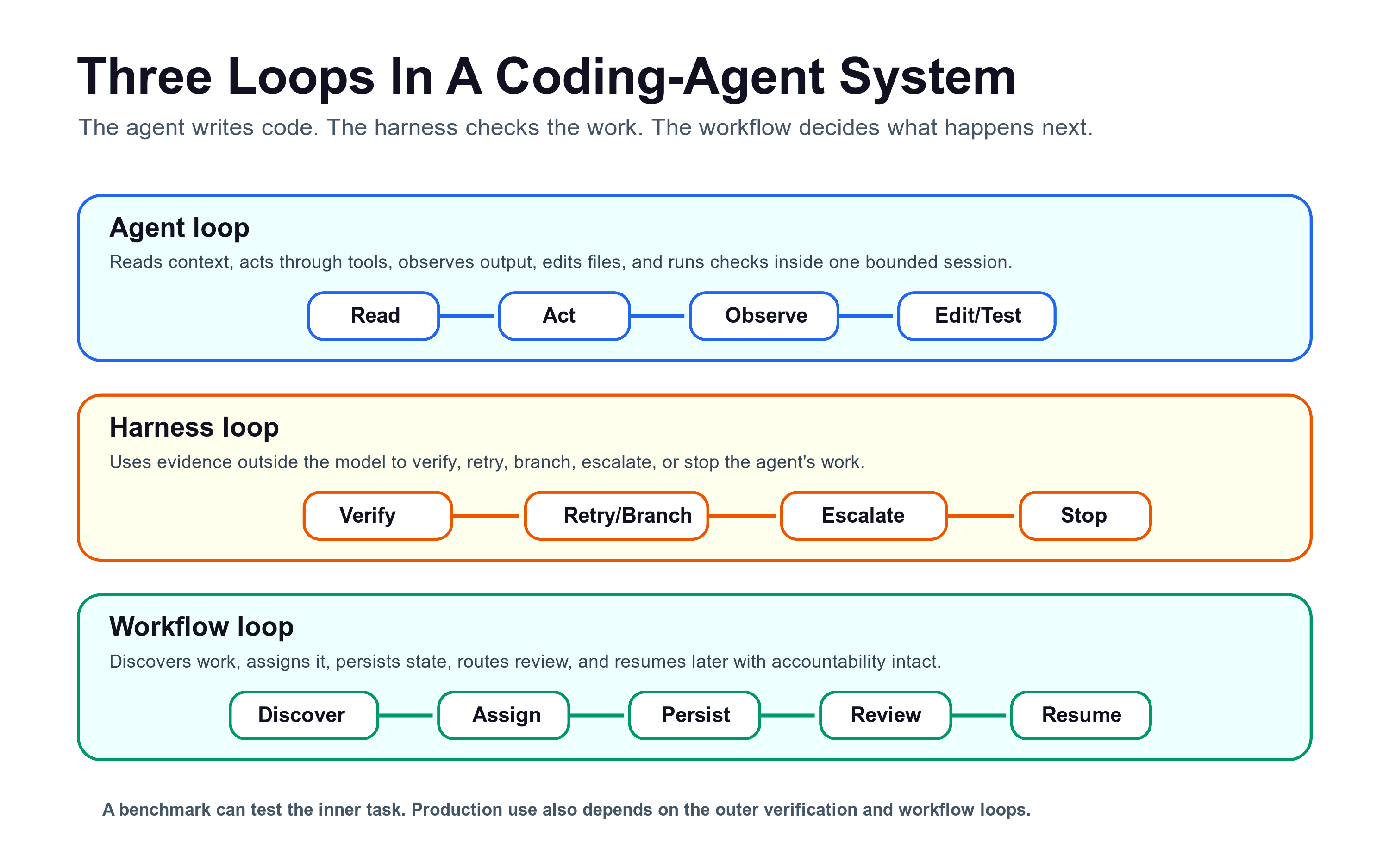
The agent loop writes code; the harness loop checks whether the work is acceptable; the workflow loop decides whether the work should exist, who reviews it, and how state persists.
Older Agent And Control Foundations
This is the layer the previous draft underdeveloped. These sources are not ornaments. They are the reason the current vocabulary makes sense.
Newell and Simon, Human Problem Solving. The starting point for problem solving as search through a structured problem space under bounded computation. Coding agents explore repo states, command outputs, and patch candidates under similar limits.
Hart, Nilsson, and Raphael, “A Formal Basis for the Heuristic Determination of Minimum Cost Paths”. The A* paper. It belongs here because loop design is partly about spending search budget intelligently: which branch, which tool call, which retry, which stop condition.
Fikes and Nilsson, “STRIPS”. Preconditions, operators, and effects. Modern tool calls look different, but safe agent design still asks what must be true before an action runs and what the action changes.
Ghallab, Nau, and Traverso, Automated Planning: Theory and Practice. A broad synthesis of planning, decomposition, actions, goals, temporal structure, and uncertainty. It gives a broader frame than “prompt a model to make a plan.”
Kaelbling, Littman, and Cassandra, “Planning and Acting in Partially Observable Stochastic Domains”. A coding agent never sees the full system. Files, logs, tests, prior runs, and issue text are observations. Context engineering is better belief-state maintenance, not larger prompts.
Erman, Hayes-Roth, Lesser, and Reddy, “The Hearsay-II Speech-Understanding System”. The canonical blackboard architecture. Multiple specialized knowledge sources coordinate through shared state. Modern versions include issue trackers, state files, memory logs, CI summaries, and review artifacts.
Rao and Georgeff, “BDI Agents: From Theory to Practice”. The belief-desire-intention model is still useful for separating what an agent knows, what it is trying to achieve, and what course of action it has committed to.
Sutton, Precup, and Singh, “Between MDPs and Semi-MDPs”. The options framework gives the clean lineage for skills: reusable, temporally extended actions that can be selected like primitives.
Horvitz, “Principles of Mixed-Initiative User Interfaces”. Good agent systems need rules for initiative: when the system proceeds, asks, pauses, escalates, or hands control back.
Parasuraman and Riley, “Humans and Automation: Use, Misuse, Disuse, Abuse”. The automation-trust paper to read before giving agents more authority. Coding-agent failures often come from overtrust, under-specification, or weak supervision rather than local syntax errors.
Sheridan, Telerobotics, Automation, and Supervisory Control. A durable treatment of human supervision over semi-autonomous systems. It is directly relevant to agent loops that operate while a human reviews only the artifacts.
LLM-Agent Primitives
This layer is closer to the earlier agent canon, but here the emphasis is on what each source adds to coding-agent loops.
WebGPT. Browse, gather evidence, cite. It is an early template for language models acting through tools rather than answering from memory.
MRKL. Modular routing across tools and symbolic systems. It foreshadows the connector/plugin layer.
ReAct. The atom of the modern agent loop: reason, act, observe.
Toolformer. Tool use as a learnable behavior, not only an inference-time wrapper.
Reflexion. Actor, evaluator, self-reflection, and memory. Coding agents need the same separation between making a change and judging it.
Tree of Thoughts. Branch, score, and backtrack. Maps onto parallel worktrees, alternate patches, and explicit search over candidate plans.
Voyager. Executable skills that accumulate over time. It is the clearest ancestor for practical skill libraries.
CodeAct. Executable code as the action language. This is central to why coding agents feel different from generic chat agents.
SWE-agent. The agent-computer interface becomes a first-class variable. The environment and harness shape the observed capability.
AI Agents That Matter. Cost, holdout validity, benchmark shortcuts, and complexity discipline. Read this before believing any agent leaderboard.
Coding-Agent Systems, Harnesses, And Configuration
This group is about the engineering layer between the model and the repo.
SWE-bench. The most widely cited benchmark for repository-level issue resolution. It belongs in this section as the benchmark that shaped coding-agent systems, not as a field study about adoption.
SWE-agent. Also belongs here because it showed that the agent-computer interface changes performance. The same model can behave differently under a different scaffold.
CodeAgent. Early repo-level, tool-integrated code generation. Useful for seeing how tool use entered repository work before the current loop vocabulary.
SICA: A Self-Improving Coding Agent. A coding agent modifies its own codebase and improves from 17 to 53 percent on a random SWE-bench Verified subset. Read it as a harness/self-improvement result, not as proof of open-ended autonomy.
Code as Agent Harness. A synthesis of the idea that code is not only the agent output; it is also part of the harness that structures reasoning, action, and verification.
Configuring Agentic AI Coding Tools. A practical taxonomy of configuration mechanisms across coding tools.
A Dataset of Agentic AI Coding Tool Configurations. Shows what configuration patterns appear in real repositories, rather than only in vendor docs.
Agent READMEs. Descriptive evidence on context files in the wild: what teams put in them, how they vary, and why they behave more like configuration than prose.
Evaluating AGENTS.md. The corrective to context-file enthusiasm. Repository instructions can reduce success and increase cost if they add irrelevant or distracting guidance.
Empirical Studies Of Use, Review, And Maintenance
This section is distinct from benchmarks. These studies look at adoption, pull requests, review, refactoring, context use, and test quality in practice.
Agentic Much?. A GitHub-scale adoption study. The current arXiv version reports 22.20 to 28.66 percent adoption across 128,018 GitHub projects. It measures traces of use, not net value.
AIDev. A dataset of agent-authored pull requests — 932,791 PRs across 116,211 repositories, produced by five agents. Keep it separate from companion studies that analyze acceptance or failure.
The Rise of AI Teammates in SE 3.0. Uses an earlier AIDev slice to study agentic PR behavior. Read for the acceptance gap and the difference between speed and accepted contribution.
Where Do AI Coding Agents Fail?. A failure study of agent-authored PRs. It is valuable because many failures are workflow failures: abandoned review, duplicate work, CI/test failures, or task mismatch.
Agentic Refactoring. Refactoring is not one thing. Agents can make local structural changes while leaving deeper design issues intact.
Are Coding Agents Generating Over-Mocked Tests?. Test quality matters because shallow verification is easy to satisfy. Agent commits change tests more often than non-agent commits (23 versus 13 percent) and add mocks more often (36 versus 26 percent).
ContextBench. Process-oriented evidence that finding relevant code and using it correctly are different skills.
SWE-ContextBench. Prior experience can help, but only when retrieved and summarized correctly. This is the right paper to read before building memory-heavy loops.
Coding Agents Are Effective Long-Context Processors. Supports the idea that agents can externalize long-context processing through filesystems and tools. Do not generalize it to all long-horizon maintenance.
Benchmarks, Stress Tests, And Safety
Benchmarks are not field studies. They measure task performance under a protocol. They are useful when the protocol is visible.
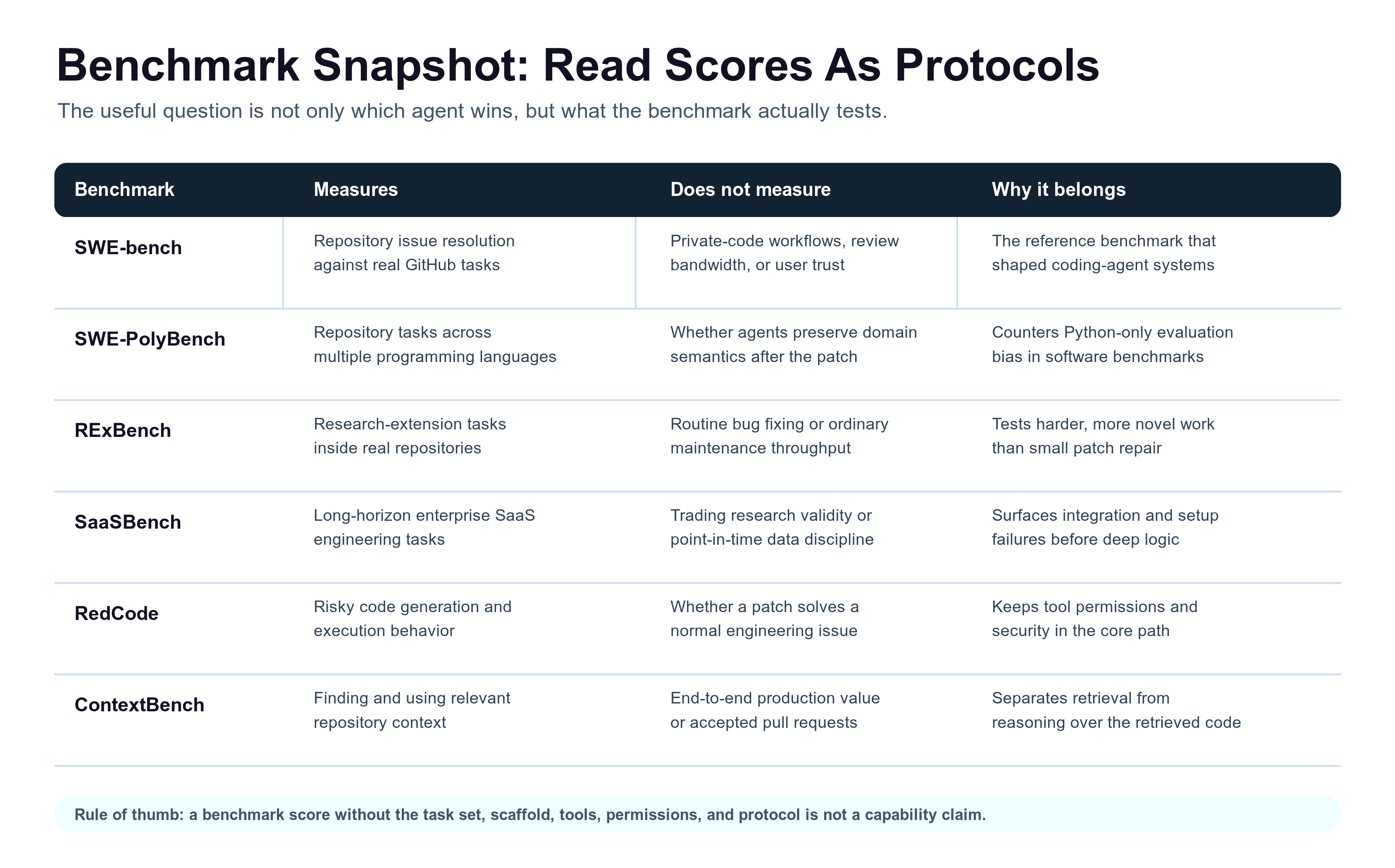
Read benchmark scores as protocol results. A benchmark can say what an agent did under a task set, scaffold, tool policy, and evaluation rule. It does not by itself establish production value, review cost, or research validity.
SWE-bench. Real GitHub issues as repository-level tasks. Essential, but easy to overread once leaderboards saturate or scaffolds diverge.
SWE-PolyBench. Multi-language repository-level evaluation. It helps counter Python-only benchmark bias.
RExBench. Research-extension tasks in real repositories. A useful ceiling check for hard, novel work.
SaaSBench. Long-horizon enterprise SaaS engineering. Its main lesson is integration: failures often happen before agents reach deep business logic.
RedCode. Risky code execution and generation. This belongs in the core path because coding agents operate tools, shells, files, and sometimes networks.
OWASP Top 10 for LLM Applications. The security frame for prompt injection, supply chain risk, sensitive data, and excessive agency.
When reading a benchmark score, ask: which task set, which date, which model, which scaffold, which tools, which permissions, and which evaluation protocol? A model score without the harness is not a product capability claim.
What This Means For ML4T Work
For ML4T readers, the near-term value of coding agents is practical: environment repair, notebook maintenance, data-loader fixes, test scaffolding, documentation updates, CI triage, and reproducible experiment plumbing. These tasks are useful because they are bounded and checkable. To make the work more reliable, we published 60+ ML4T agent skills.
The risky step is letting an agent mutate the research claim. In trading and ML, the dangerous errors are often leakage, wrong timestamps, stale data assumptions, broken evaluation windows, accidental survivorship, weak baselines, or transaction-cost assumptions that no longer match the text.
The failure is rarely a syntax error. A more typical case: an agent makes a failing data-loader test pass by dropping the tickers that stopped returning history. The suite goes green, and the backtest quietly runs on survivors only. The code is correct; the research claim has changed.
For an ML4T notebook, loader, or backtest change, an agent-generated patch should record:
data source and snapshot date;
timestamp convention and decision-time availability;
label definition;
train/test split or walk-forward window;
baseline comparison;
transaction-cost assumption where relevant;
exact command to reproduce the result;
files changed and why;
tests added or modified;
reviewer note on whether the research claim changed.
Do not delegate changes that redefine the target variable, change the backtest window, select the best run after repeated iteration, add data that would not have been known at decision time, or rewrite the published claim to fit the new output. Those choices belong to the research process, not to the coding loop.
On Tuesday, July 7, I am teaching a free Maven Lightning Lesson, Getting stuff done with coding agents. The lesson is the practical companion to this reading list: how to turn an ambiguous goal into a scoped work unit, keep state across sessions, use review gates, and make agent work legible enough that a human can still own the result.
The same boundary sits at the center of Machine Learning for Trading: From Research to Production, the cohort course I am running this summer: it works nine case studies through that exact division of labor — what you can hand to the loop, and what stays with you because it decides whether the result is real. Watch the video overview.
Compressed Reading Path
If the full list is too much, start here:
Osmani, Ronacher, Willison, Böckeler, and Huntley for the current loop and harness debate.
Newell/Simon, POMDPs, Hearsay-II, options, mixed initiative, automation misuse, and supervisory control for the older design problems.
ReAct, Reflexion, Voyager, CodeAct, SWE-agent, and AI Agents That Matter for the LLM-agent mechanism.
Evaluating AGENTS.md, Agentic Much?, AIDev, Where Do AI Coding Agents Fail?, Agentic Refactoring, Over-mocked Tests, and ContextBench for field evidence.
SWE-bench, RExBench, SaaSBench, SWE-PolyBench, and RedCode for benchmark and safety constraints.
The practical result is a design rule: decide what the agent may change, define how the harness checks it, preserve the evidence needed for review, and keep the research claim outside the automation boundary.